
Path: blob/master/site/zh-cn/tutorials/load_data/video.ipynb
38523 views
Copyright 2022 The TensorFlow Authors.
加载视频数据
 在 GitHub 上查看源代码
在 GitHub 上查看源代码本教程演示如何使用 UCF101 人体动作数据集加载和预处理 AVI 视频数据。当您对数据进行预处理后,就可以将其用于视频分类/识别、字幕或聚类等任务。原始数据集包含从 YouTube 收集的具有 101 个类别的真实动作视频,包括演奏大提琴、刷牙和化眼妆。您将学习如何:
从 ZIP 文件加载数据。
从视频文件中读取帧序列。
呈现视频数据。
封装帧生成器
tf.data.Dataset。
本视频加载和预处理教程是 TensorFlow 视频教程系列的第一部分。下面是其他三个教程:
构建用于视频分类的 3D CNN 模型:请注意,本教程使用分解 3D 数据的空间和时间方面的 (2+1)D CNN;如果使用 MRI 扫描等体数据,请考虑使用 3D CNN 而不是 (2+1)D CNN。
用于流式动作识别的 MoViNet:熟悉 TF Hub 上提供的 MoViNet 模型。
使用 MoViNet 进行视频分类的迁移学习:本教程介绍了如何使用预训练的视频分类模型,该模型是在具有 UCF-101 数据集的不同数据集上训练的。
安装
首先,安装和导入一些必要的库,包括:用于检查 ZIP 文件内容的 remotezip,用于使用进度条的 tqdm,用于处理视频文件的 OpenCV,以及用于在 Jupyter 笔记本中嵌入数据的 tensorflow_docs。
下载 UCF101 数据集的子集
UCF101 数据集包含 101 类不同动作的视频,主要用于动作识别。您将在此演示中使用这些类别的一个子集。
上面的网址包含一个带有 UCF 101 数据集的 ZIP 文件。创建一个使用 remotezip 库的函数来检查该 URL 中 ZIP 文件的内容:
先从几个视频和有限数量的类开始训练。运行上述代码块后,请注意类名包含在每个视频的文件名中。
定义从文件名中检索类名的 get_class 函数。然后,创建一个名为 get_files_per_class 的函数,它会将所有文件的列表(上面的 files)转换为列出每个类的文件的字典:
获得每个类的文件列表后,您可以选择要使用多少个类,以及每个类需要多少视频,以创建数据集。
创建一个名为 select_subset_of_classes 的新函数,它会选择数据集中存在的类的子集并在每个类中选择特定数量的文件:
定义将视频拆分为训练集、验证集和测试集的辅助函数。视频从带有 ZIP 文件的网址下载,并放置在各自的子目录中。
以下函数会返回尚未放入数据子集的剩余数据。它允许您将剩余的数据放在下一个指定的数据子集中。
下面的 download_ufc_101_subset 函数允许您下载 UCF101 数据集的子集并将其拆分为训练集、验证集和测试集。您可以指定要使用的类的数量。splits 参数允许您传入一个字典,其中键值是子集的名称(例如:“train”)和您希望每个类拥有的视频数量。
下载数据后,您现在应该拥有了一个 UCF101 数据集子集的副本。运行以下代码即可打印您在所有数据子集中拥有的视频总数。
您现在还可以预览数据文件的目录。
从每个视频文件创建帧
frames_from_video_file 函数会将视频拆分为帧,从视频文件中读取随机选择的 n_frames 跨度,并将它们作为 NumPy array 返回。要减少内存和计算开销,请选择少量帧。此外,请从每个视频中选取相同数量的帧,这样可以更轻松地处理批量数据。
呈现视频数据
frames_from_video_file 函数会将一组帧作为 NumPy 数组返回。尝试在 Patrick Gillett 的 Wikimedia{:.external} 的新视频中使用此函数:
除了查看此视频外,您还可以显示 UCF-101 数据。为此,请运行以下代码:
接下来,定义 FrameGenerator 类以创建一个可迭代对象,该对象可以将数据输入 TensorFlow 数据流水线。生成器 (__call__) 函数产生由 frames_from_video_file 生成的帧数组以及与帧集相关联的标签的独热编码向量。
在将 FrameGenerator 对象封装为 TensorFlow Dataset 对象之前对其进行测试。此外,对于训练数据集,请确保启用训练模式,以便对数据进行重排。
最后,创建一个 TensorFlow 数据输入流水线。您从生成器对象创建的此流水线允许您将数据输入深度学习模型。在此视频流水线中,每个元素都是一组单独的帧及其关联标签。
检查标签是否重排。
配置数据集以提高性能
使用缓冲预提取,以便从磁盘产生数据,而不会阻塞 I/O。下面是可以在加载数据时使用的两个重要函数:
Dataset.cache:在第一个周期期间从磁盘加载图像后,它会将这些图像保留在内存中。该函数确保在训练模型时数据集不会成为瓶颈。如果数据集太大无法装入内存,您也可以使用此方法创建高性能的磁盘缓存。Dataset.prefetch:在训练时重叠数据预处理和模型执行。有关详细信息,请参阅使用tf.data提升性能。
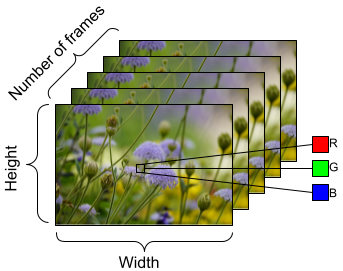
要准备馈送到模型的数据,请使用批处理,如下所示。请注意,在处理视频数据(例如 AVI 文件)时,数据应形成五维对象。这些维度如下:[batch_size, number_of_frames, height, width, channels]。相比之下,图像将具有四个维度:[batch_size, height, width, channels]。下图说明了如何表示视频数据的形状。
后续步骤
现在,您已经创建了带有标签的视频帧的 TensorFlow Dataset,您可以将其与深度学习模型一起使用。以下使用预训练的 EfficientNet{:.external} 的分类模型可在几分钟内训练到较高准确率:
要详细了解如何在 TensorFlow 中处理视频数据,请查看以下教程: