
Path: blob/master/site/zh-cn/tutorials/text/image_captioning.ipynb
38549 views
Copyright 2018 The TensorFlow Authors.
<style> td { text-align: center; } th { text-align: center; } </style>
使用视觉注意力生成图像描述
 在 GitHub 上查看源代码
在 GitHub 上查看源代码给定一个类似以下示例的图像,我们的目标是生成一个类似“一名正在冲浪的冲浪者”的描述。
 |
| 一个冲浪的人,来自 Wikimedia |
|---|
此处使用的模型架构的灵感来自 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention,但已更新为使用 2 层 Transformer 解码器。要充分利用本教程,您应该对文本生成、seq2seq 模型和注意力或 Transformer 有一定的经验。
本教程中构建的模型架构如下所示。从图像中提取特征,并传递到 Transformer 解码器的交叉注意力层。
| 模型架构 |
|---|
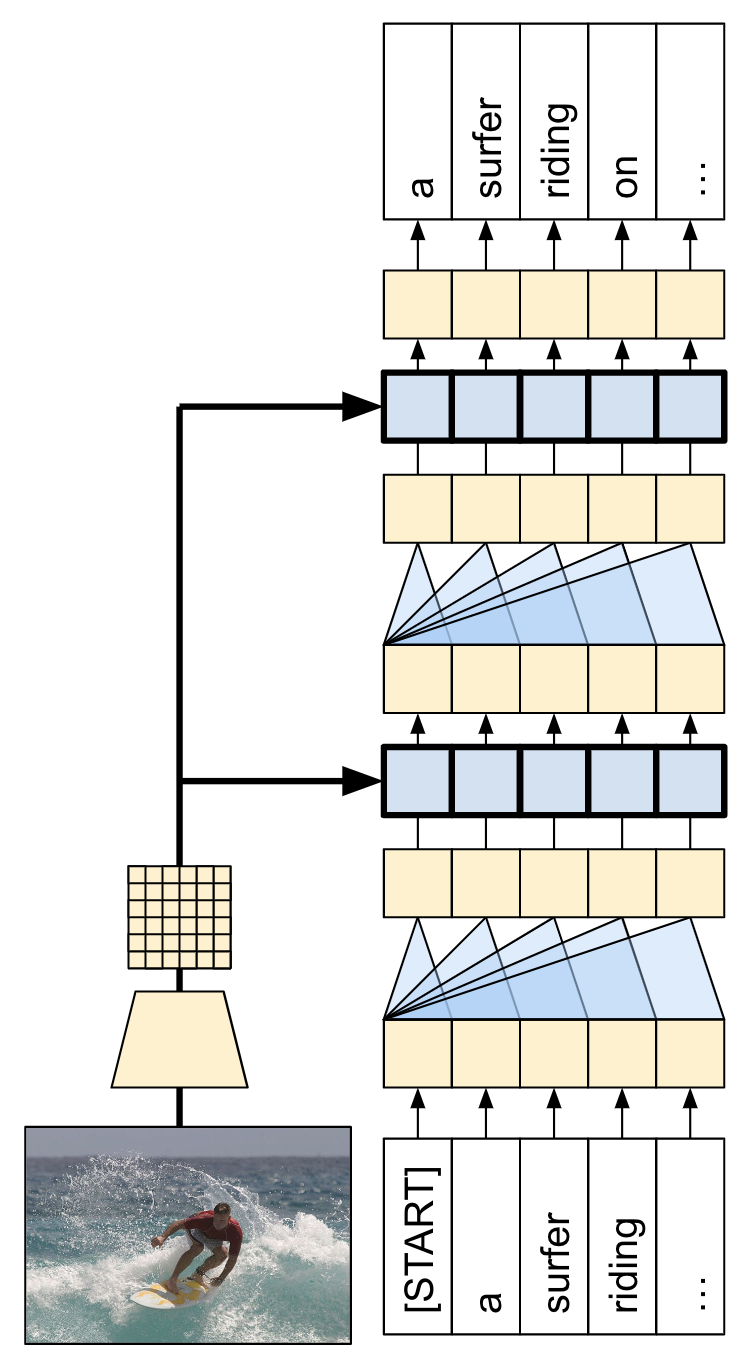 |
Transformer 解码器主要由注意力层构建。它使用自注意力处理正在生成的序列,并使用交叉注意力处理图像。
通过检查交叉注意力层的注意力权重,您将看到模型在生成单词时正在查看图像的哪些部分。
此笔记本是一个端到端示例。当您运行此笔记本时,它会下载数据集、提取和缓存图像特征,并训练解码器模型。随后,它会使用该模型在新的图像上生成描述。
安装
本教程使用大量导入,主要用于加载数据集。
[可选] 数据处理
本部分下载描述数据集并为训练做准备。它将输入文本词例化,并缓存通过预训练的特征提取程序模型运行所有图像的结果。理解本部分中的所有内容并不是非常重要。
选择数据集
本教程旨在提供数据集的选择。Flickr8k 或 Conceptual Captions 数据集的一小部分。这两个数据集需要从头开始下载和转换,但是将教程转换为使用 TensorFlow 数据集中可用的描述数据集(Coco Captions 和完整的 Conceptual Captions)并不难。
Flickr8k
Conceptual Captions
下载数据集
Flickr8k 是一个不错的选择,因为它每个图像包含 5 个描述,下载更少,数据更多。
上面两个数据集的加载程序都返回包含 (image_path, captions) 对的 tf.data.Dataset。Flickr8k 数据集每个图像包含 5 个描述,而 Conceptual Captions 有 1 个:
图像特征提取程序
您将使用图像模型(在 imagenet 上预训练)从每个图像中提取特征。该模型被训练为图像分类器,但设置 include_top=False 会返回没有最终分类层的模型,因此您可以使用特征映射的最后一层:
下面是一个加载图像并为模型调整大小的函数:
该模型为输入批次中的每个图像返回一个特征映射:
设置文本分词器/向量化程序
使用 TextVectorization 层将文本描述转换为整数序列,步骤如下:
使用 adapt 迭代所有描述,将描述拆分为字词,并计算最热门字词的词汇表。
通过将每个字词映射到它在词汇表中的索引对所有描述进行词例化。所有输出序列将被填充到长度 50。
创建字词到索引和索引到字词的映射以显示结果。
准备数据集
train_raw 和 test_raw 数据集包含一对多 (image, captions) 对。
此函数将复制图像,因此描述中有 1:1 的图像:
为了与 keras 训练兼容,数据集应包含 (inputs, labels) 对。对于文本生成,词例既是输入又是标签,且移动了一步。此函数会将 (images, texts) 对转换为 ((images, input_tokens), label_tokens) 对:
此函数会将运算添加到数据集。步骤如下:
加载图像(忽略加载失败的图像)。
复制图像以匹配描述的数量。
对
image, caption对执行重排和重新批处理。将文本词例化,移动词例并添加
label_tokens。将文本从
RaggedTensor表示转换为填充的密集Tensor表示。
您可以在模型中安装特征提取程序并在数据集上进行训练,如下所示:
[可选] 缓存图像特征
由于图像特征提取程序没有更改,并且本教程没有使用图像增强,可以缓存图像特征。文本词例化也是如此。在训练和验证期间,每个周期都可以重新获得设置缓存所需的时间。下面的代码定义了两个函数 (save_dataset 和 load_dataset):
准备好训练的数据
在这些预处理步骤之后,下面是数据集:
数据集现在返回适合使用 keras 进行训练的 (input, label) 对。inputs 是 (images, input_tokens) 对。images 已使用特征提取程序模型进行处理。对于 input_tokens 中的每个位置,模型会查看到目前为止的文本,并尝试预测在 labels 中相同位置排列的下一个文本。
输入词例和标签相同,只移动了 1 步:
Transformer 解码器模型
此模型假设预训练的图像编码器已足够,并且只专注于构建文本解码器。本教程使用 2 层 Transformer 解码器。
这些实现几乎与 Transformer 教程中的实现相同。请参阅该教程以了解更多详细信息。
| Transformer 编码器和解码器 |
|---|
| |
该模型将分以下三个主要部分实现:
输入 - 词例嵌入向量和位置编码 (
SeqEmbedding)。解码器 - Transformer 解码器层堆叠 (
DecoderLayer),其中每层包含:一个因果自注意力层 (
CausalSelfAttention),其中,每个输出位置都可以注意目前为止的输出。一个交叉注意力层 (
CrossAttention),其中每个输出位置都可以注意输入图像。一个前馈网络 (
FeedForward) 层,它进一步独立处理每个输出位置。
输出 - 对输出词汇的多类分类。
输入
输入文本已被拆分为词例并转换为 ID 序列。
请记住,与 CNN 或 RNN 不同,Transformer 的注意力层对序列的顺序是不变的。如果没有一些位置输入,它只会看到无序集而不是序列。因此,除了每个词例 ID 的简单向量嵌入之外,嵌入向量层还将包括序列中每个位置的嵌入向量。
SeqEmbedding 层定义如下:
它查找每个词例的嵌入向量。
它为每个序列位置查找一个嵌入向量。
将两者相加。
它使用
mask_zero=True来初始化模型的 keras-mask。
注:此实现学习位置嵌入向量,而不是像 Transformer 教程中那样使用固定嵌入向量。学习嵌入向量的代码略少,但不能泛化到更长的序列。
解码器
解码器是一个标准的 Transformer 解码器,它包含 DecoderLayers 堆叠,其中每层包含三个子层:CausalSelfAttention、CrossAttention 和 FeedForward。实现几乎与 Transformer 教程相同,请参阅该教程以了解更多详细信息。
CausalSelfAttention 层如下:
CrossAttention 层如下。注意 return_attention_scores 的使用。
FeedForward 层如下。请记住,layers.Dense 层应用于输入的最后一个轴。输入的形状是 (batch, sequence, channels),因此它会自动在 batch 和 sequence 轴上逐点应用。
接下来将这三层排列成一个更大的 DecoderLayer。每个解码器层依次应用三个较小的层。在每个子层之后,out_seq 的形状是 (batch, sequence, channels)。解码器层还会返回 attention_scores 以用于后续呈现。
输出
输出层至少需要一个 layers.Dense 层来为每个位置的每个词例生成对数预测。
但是,您可以添加一些其他功能来改善效果:
处理不良词例:模型将生成文本。它绝不应该生成填充、未知或起始词例(
''、'[UNK]'、'[START]')。因此,将这些偏差设置为较大的负值。注:您还需要在损失函数中忽略这些词例。
智能初始化:密集层的默认初始化将给出一个模型,此模型最初以几乎均匀的可能性预测每个词例。实际词例分布远非均匀。输出层初始偏差的最佳值是每个词例的概率的对数。因此,请包括一种
adapt方法来计算词例并设置最佳初始偏差。这可以减少从均匀分布的熵 (log(vocabulary_size)) 到分布的边际熵 (-p*log(p)) 的初始损失。
智能初始化将显著减少初始损失:
构建模型
要构建模型,您需要结合以下几个部分:
图像
feature_extractor和文本tokenizer。seq_embedding层,将词例 ID 批次转换为向量(batch, sequence, channels)。将处理文本和图像数据的
DecoderLayers层堆叠。output_layer返回下一个字词应该是什么的逐点预测。
当您调用模型进行训练时,它会收到一个 image, txt 对。为了让这个函数更有用,需要灵活处理输入:
如果图像有 3 个通道,则通过特征提取程序运行它。否则,假设它已经存在。类似地
如果文本的数据类型为
tf.string,则通过分词器运行它。
之后,运行模型只需以下几个步骤:
展平提取的图像特征,以便它们可以输入到解码器层。
查找词例嵌入向量。
在图像特征和文本嵌入向量上运行
DecoderLayer堆叠。运行输出层以预测每个位置的下一个词例。
生成描述
在开始训练之前,编写一些代码来生成描述。您将使用它来查看训练的进展。
首先,下载一个测试图像:
要使用此模型为图像添加描述,请执行以下操作:
提取
img_features使用
[START]词例初始化输出词例列表。将
img_features和tokens传递到模型中。它返回一个对数列表。
根据这些对数选择下一个词例。
将其添加到词例列表中,然后继续循环。
如果它生成一个
'[END]'词例,则跳出循环。
因此,添加一个“简单”的方法来实现此目标:
以下是为该图像生成的一些描述,该模型未经训练,因此它们还没有太大意义:
温度参数允许您在 3 种模式之间进行插值:
贪婪解码 (
temperature=0.0) - 在每一步选择最有可能的下一个词例。根据 logit (
temperature=1.0) 随机抽样。均匀随机抽样 (
temperature >> 1.0)。
由于模型未经训练,并且它使用基于频率的初始化,“贪婪”输出(第一个)通常只包含最常见的词例:['a', '.', '[END]']。
训练
要训练模型,您需要几个额外的组件:
损失和指标
优化器
可选回调
损失和指标
下面是一个遮盖损失和准确率的实现:
在计算损失的掩码时,请注意 loss < 1e8。此术语丢弃了 banned_tokens 的人为不可能高损失。
回调
对于训练设置期间的反馈,使用 keras.callbacks.Callback 在每个周期结束时为冲浪者图像生成一些描述。
像之前的示例一样,它生成三个输出字符串,第一个是“greedy”,在每个步骤中选择 logit 的 argmax。
当模型开始过拟合时,还可以使用 callbacks.EarlyStopping 终止训练。
训练
配置并执行训练。
如需更频繁的报告,请使用 Dataset.repeat() 方法,并将 steps_per_epoch 和 validation_steps 参数设置为 Model.fit。
在 Flickr8k 上使用此设置,数据集上的全通是 900 多个批次,但下面的报告周期为 100 步。
绘制训练运行的损失和准确率:
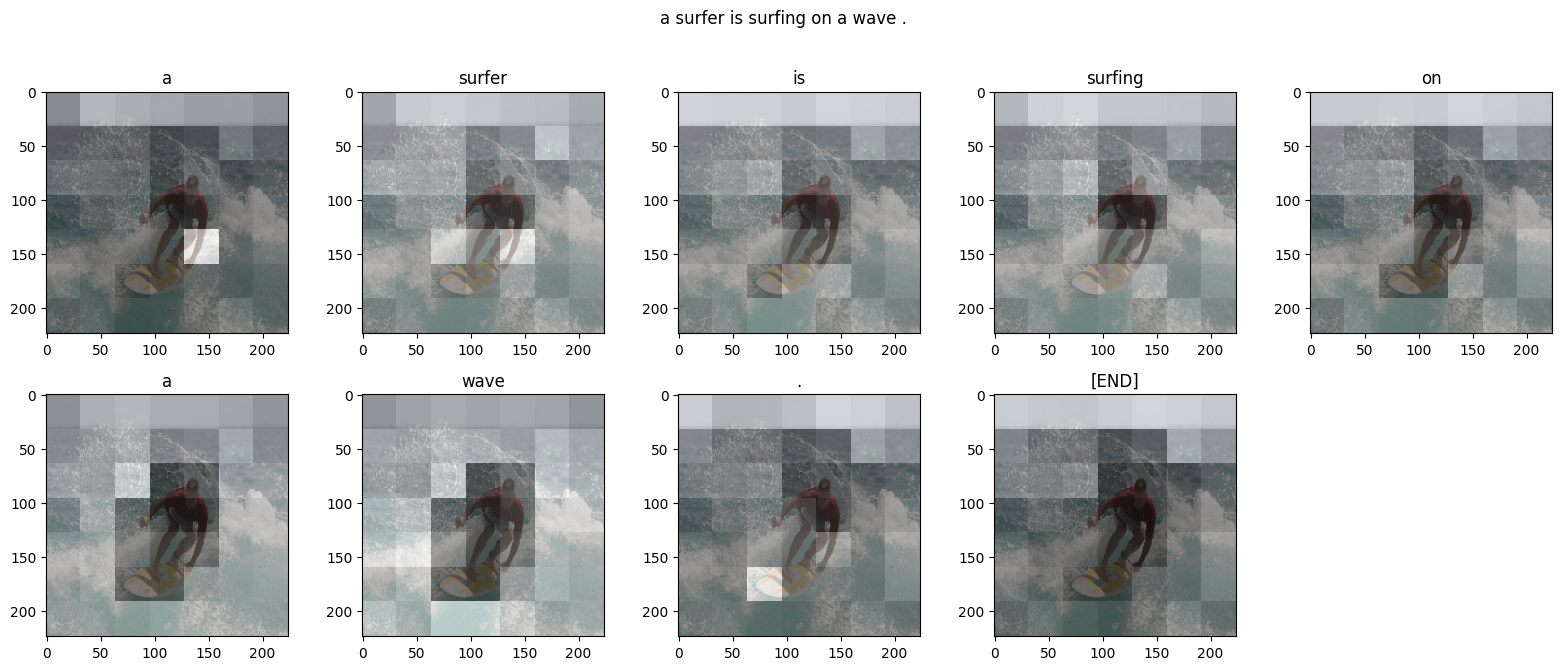
注意力图
现在,使用经过训练的模型,在图像上运行 simple_gen 方法:
将输出拆分回词例:
每个 DecoderLayers 都为其 CrossAttention 层缓存注意力分数。每个注意力图的形状为 (batch=1, heads, sequence, image):
因此,沿 batch 轴堆叠映射,然后在 (batch, heads) 轴上计算平均值,同时将 image 轴拆分回 height, width:
现在,对于每个序列预测,您都有一个注意力图。每个映射中的值总和应为 1。
下面是模型在生成输出的每个词例时集中注意力的地方:
现在,将它们组合成一个更有用的函数:
在自己的图像上进行尝试
为了增加趣味性,下面会提供一个方法,让您可以通过刚才训练的模型为您自己的图像生成描述。请记住,这个模型是使用较少数据训练的,而您的图像可能与训练数据不同(因此,请做好心理准备,您可能会得到奇怪的结果!)