
Path: blob/master/site/zh-cn/tutorials/text/transformer.ipynb
38553 views
Copyright 2019 The TensorFlow Authors.
理解语言的 Transformer 模型
 在 Github 上查看源代码
在 Github 上查看源代码Note: 我们的 TensorFlow 社区翻译了这些文档。因为社区翻译是尽力而为, 所以无法保证它们是最准确的,并且反映了最新的 官方英文文档。如果您有改进此翻译的建议, 请提交 pull request 到 tensorflow/docs GitHub 仓库。要志愿地撰写或者审核译文,请加入 [email protected] Google Group
本教程训练了一个 Transformer 模型 用于将葡萄牙语翻译成英语。这是一个高级示例,假定您具备文本生成(text generation)和 注意力机制(attention) 的知识。
Transformer 模型的核心思想是自注意力机制(self-attention)——能注意输入序列的不同位置以计算该序列的表示的能力。Transformer 创建了多层自注意力层(self-attetion layers)组成的堆栈,下文的*按比缩放的点积注意力(Scaled dot product attention)和多头注意力(Multi-head attention)*部分对此进行了说明。
一个 transformer 模型用自注意力层而非 RNNs 或 CNNs 来处理变长的输入。这种通用架构有一系列的优势:
它不对数据间的时间/空间关系做任何假设。这是处理一组对象(objects)的理想选择(例如,星际争霸单位(StarCraft units))。
层输出可以并行计算,而非像 RNN 这样的序列计算。
远距离项可以影响彼此的输出,而无需经过许多 RNN 步骤或卷积层(例如,参见场景记忆 Transformer(Scene Memory Transformer))
它能学习长距离的依赖。在许多序列任务中,这是一项挑战。
该架构的缺点是:
对于时间序列,一个单位时间的输出是从整个历史记录计算的,而非仅从输入和当前的隐含状态计算得到。这可能效率较低。
如果输入确实有时间/空间的关系,像文本,则必须加入一些位置编码,否则模型将有效地看到一堆单词。
在此 notebook 中训练完模型后,您将能输入葡萄牙语句子,得到其英文翻译。

设置输入流水线(input pipeline)
使用 TFDS 来导入 葡萄牙语-英语翻译数据集,该数据集来自于 TED 演讲开放翻译项目.
该数据集包含来约 50000 条训练样本,1100 条验证样本,以及 2000 条测试样本。
从训练数据集创建自定义子词分词器(subwords tokenizer)。
如果单词不在词典中,则分词器(tokenizer)通过将单词分解为子词来对字符串进行编码。
将开始和结束标记(token)添加到输入和目标。
Note:为了使本示例较小且相对较快,删除长度大于40个标记的样本。
.map() 内部的操作以图模式(graph mode)运行,.map() 接收一个不具有 numpy 属性的图张量(graph tensor)。该分词器(tokenizer)需要将一个字符串或 Unicode 符号,编码成整数。因此,您需要在 tf.py_function 内部运行编码过程,tf.py_function 接收一个 eager 张量,该 eager 张量有一个包含字符串值的 numpy 属性。
位置编码(Positional encoding)
因为该模型并不包括任何的循环(recurrence)或卷积,所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。
位置编码向量被加到嵌入(embedding)向量中。嵌入表示一个 d 维空间的标记,在 d 维空间中有着相似含义的标记会离彼此更近。但是,嵌入并没有对在一句话中的词的相对位置进行编码。因此,当加上位置编码后,词将基于它们含义的相似度以及它们在句子中的位置,在 d 维空间中离彼此更近。
参看 位置编码 的 notebook 了解更多信息。计算位置编码的公式如下:
遮挡(Masking)
遮挡一批序列中所有的填充标记(pad tokens)。这确保了模型不会将填充作为输入。该 mask 表明填充值 0 出现的位置:在这些位置 mask 输出 1,否则输出 0。
前瞻遮挡(look-ahead mask)用于遮挡一个序列中的后续标记(future tokens)。换句话说,该 mask 表明了不应该使用的条目。
这意味着要预测第三个词,将仅使用第一个和第二个词。与此类似,预测第四个词,仅使用第一个,第二个和第三个词,依此类推。
按比缩放的点积注意力(Scaled dot product attention)
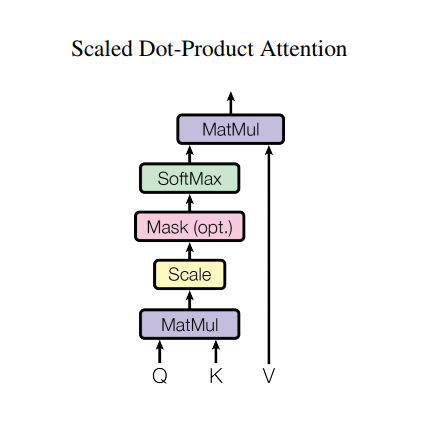
Transformer 使用的注意力函数有三个输入:Q(请求(query))、K(主键(key))、V(数值(value))。用于计算注意力权重的等式为:
点积注意力被缩小了深度的平方根倍。这样做是因为对于较大的深度值,点积的大小会增大,从而推动 softmax 函数往仅有很小的梯度的方向靠拢,导致了一种很硬的(hard)softmax。
例如,假设 Q 和 K 的均值为0,方差为1。它们的矩阵乘积将有均值为0,方差为 dk。因此,dk 的平方根被用于缩放(而非其他数值),因为,Q 和 K 的矩阵乘积的均值本应该为 0,方差本应该为1,这样会获得一个更平缓的 softmax。
遮挡(mask)与 -1e9(接近于负无穷)相乘。这样做是因为遮挡与缩放的 Q 和 K 的矩阵乘积相加,并在 softmax 之前立即应用。目标是将这些单元归零,因为 softmax 的较大负数输入在输出中接近于零。
当 softmax 在 K 上进行归一化后,它的值决定了分配到 Q 的重要程度。
输出表示注意力权重和 V(数值)向量的乘积。这确保了要关注的词保持原样,而无关的词将被清除掉。
将所有请求一起传递。
多头注意力(Multi-head attention)
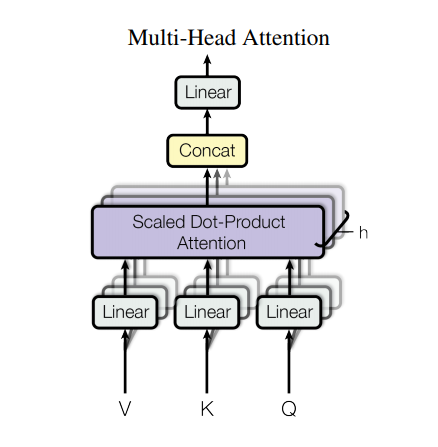
多头注意力由四部分组成:
线性层并分拆成多头。
按比缩放的点积注意力。
多头及联。
最后一层线性层。
每个多头注意力块有三个输入:Q(请求)、K(主键)、V(数值)。这些输入经过线性(Dense)层,并分拆成多头。
将上面定义的 scaled_dot_product_attention 函数应用于每个头(进行了广播(broadcasted)以提高效率)。注意力这步必须使用一个恰当的 mask。然后将每个头的注意力输出连接起来(用tf.transpose 和 tf.reshape),并放入最后的 Dense 层。
Q、K、和 V 被拆分到了多个头,而非单个的注意力头,因为多头允许模型共同注意来自不同表示空间的不同位置的信息。在分拆后,每个头部的维度减少,因此总的计算成本与有着全部维度的单个注意力头相同。
创建一个 MultiHeadAttention 层进行尝试。在序列中的每个位置 y,MultiHeadAttention 在序列中的所有其他位置运行所有8个注意力头,在每个位置y,返回一个新的同样长度的向量。
点式前馈网络(Point wise feed forward network)
点式前馈网络由两层全联接层组成,两层之间有一个 ReLU 激活函数。
编码与解码(Encoder and decoder)

Transformer 模型与标准的具有注意力机制的序列到序列模型(sequence to sequence with attention model),遵循相同的一般模式。
输入语句经过
N个编码器层,为序列中的每个词/标记生成一个输出。解码器关注编码器的输出以及它自身的输入(自注意力)来预测下一个词。
编码器层(Encoder layer)
每个编码器层包括以下子层:
多头注意力(有填充遮挡)
点式前馈网络(Point wise feed forward networks)。
每个子层在其周围有一个残差连接,然后进行层归一化。残差连接有助于避免深度网络中的梯度消失问题。
每个子层的输出是 LayerNorm(x + Sublayer(x))。归一化是在 d_model(最后一个)维度完成的。Transformer 中有 N 个编码器层。
解码器层(Decoder layer)
每个解码器层包括以下子层:
遮挡的多头注意力(前瞻遮挡和填充遮挡)
多头注意力(用填充遮挡)。V(数值)和 K(主键)接收编码器输出作为输入。Q(请求)接收遮挡的多头注意力子层的输出。
点式前馈网络
每个子层在其周围有一个残差连接,然后进行层归一化。每个子层的输出是 LayerNorm(x + Sublayer(x))。归一化是在 d_model(最后一个)维度完成的。
Transformer 中共有 N 个解码器层。
当 Q 接收到解码器的第一个注意力块的输出,并且 K 接收到编码器的输出时,注意力权重表示根据编码器的输出赋予解码器输入的重要性。换一种说法,解码器通过查看编码器输出和对其自身输出的自注意力,预测下一个词。参看按比缩放的点积注意力部分的演示。
编码器(Encoder)
编码器 包括:
输入嵌入(Input Embedding)
位置编码(Positional Encoding)
N 个编码器层(encoder layers)
输入经过嵌入(embedding)后,该嵌入与位置编码相加。该加法结果的输出是编码器层的输入。编码器的输出是解码器的输入。
解码器(Decoder)
解码器包括:
输出嵌入(Output Embedding)
位置编码(Positional Encoding)
N 个解码器层(decoder layers)
目标(target)经过一个嵌入后,该嵌入和位置编码相加。该加法结果是解码器层的输入。解码器的输出是最后的线性层的输入。
创建 Transformer
Transformer 包括编码器,解码器和最后的线性层。解码器的输出是线性层的输入,返回线性层的输出。
配置超参数(hyperparameters)
为了让本示例小且相对较快,已经减小了num_layers、 d_model 和 dff 的值。
Transformer 的基础模型使用的数值为:num_layers=6,d_model = 512,dff = 2048。关于所有其他版本的 Transformer,请查阅论文。
Note:通过改变以下数值,您可以获得在许多任务上达到最先进水平的模型。
优化器(Optimizer)
根据论文中的公式,将 Adam 优化器与自定义的学习速率调度程序(scheduler)配合使用。
损失函数与指标(Loss and metrics)
由于目标序列是填充(padded)过的,因此在计算损失函数时,应用填充遮挡非常重要。
训练与检查点(Training and checkpointing)
创建检查点的路径和检查点管理器(manager)。这将用于在每 n 个周期(epochs)保存检查点。
目标(target)被分成了 tar_inp 和 tar_real。tar_inp 作为输入传递到解码器。tar_real 是位移了 1 的同一个输入:在 tar_inp 中的每个位置,tar_real 包含了应该被预测到的下一个标记(token)。
例如,sentence = "SOS A lion in the jungle is sleeping EOS"
tar_inp = "SOS A lion in the jungle is sleeping"
tar_real = "A lion in the jungle is sleeping EOS"
Transformer 是一个自回归(auto-regressive)模型:它一次作一个部分的预测,然后使用到目前为止的自身的输出来决定下一步要做什么。
在训练过程中,本示例使用了 teacher-forcing 的方法(就像文本生成教程中一样)。无论模型在当前时间步骤下预测出什么,teacher-forcing 方法都会将真实的输出传递到下一个时间步骤上。
当 transformer 预测每个词时,*自注意力(self-attention)*功能使它能够查看输入序列中前面的单词,从而更好地预测下一个单词。
为了防止模型在期望的输出上达到峰值,模型使用了前瞻遮挡(look-ahead mask)。
葡萄牙语作为输入语言,英语为目标语言。
评估(Evaluate)
以下步骤用于评估:
用葡萄牙语分词器(
tokenizer_pt)编码输入语句。此外,添加开始和结束标记,这样输入就与模型训练的内容相同。这是编码器输入。解码器输入为
start token == tokenizer_en.vocab_size。计算填充遮挡和前瞻遮挡。
解码器通过查看编码器输出和它自身的输出(自注意力)给出预测。选择最后一个词并计算它的 argmax。
将预测的词连接到解码器输入,然后传递给解码器。
在这种方法中,解码器根据它预测的之前的词预测下一个。
Note:这里使用的模型具有较小的能力以保持相对较快,因此预测可能不太正确。要复现论文中的结果,请使用全部数据集,并通过修改上述超参数来使用基础 transformer 模型或者 transformer XL。
您可以为 plot 参数传递不同的层和解码器的注意力模块。
总结
在本教程中,您已经学习了位置编码,多头注意力,遮挡的重要性以及如何创建一个 transformer。
尝试使用一个不同的数据集来训练 transformer。您可也可以通过修改上述的超参数来创建基础 transformer 或者 transformer XL。您也可以使用这里定义的层来创建 BERT 并训练最先进的模型。此外,您可以实现 beam search 得到更好的预测。