
Path: blob/master/site/zh-cn/tutorials/understanding/sngp.ipynb
39036 views
Copyright 2021 The TensorFlow Authors.
使用 SNGP 进行不确定性感知深度学习
 在 GitHub 上查看源代码
在 GitHub 上查看源代码在诸如医疗决策制定和自动驾驶等安全性至关重要的 AI 应用中,或者在数据存在固有噪声的情况(例如自然语言理解)下,深度分类器必须能够可靠地量化其不确定性。深度分类器应能感知到自身的局限性,并能意识到何时应将控制权交给人类专家。本教程展示了如何使用称为谱归一化神经高斯过程 (SNGP{.external}) 的技术来提高深度分类器量化不确定性的能力。
SNGP 的核心思想是通过对网络应用简单的修改来提高深度分类器的距离感知。模型的距离感知是衡量其预测概率能否准确反映测试样本与训练数据间距离的指标。这是黄金标准下的概率模型(例如,具有 RBF 内核的高斯过程{.external})常需的属性,但在具有深度神经网络的模型中却缺少这一属性。SNGP 提供了一种将这种高斯过程行为注入到深度分类器中,同时能够保持其预测准确率的简单方式。
本教程在 scikit-learn 的双月{.external} 数据集上实现了一个基于深度残差网络 (ResNet) 的 SNGP 模型,并将其不确定性表面与其他两种热门不确定性方式的不确定性表面进行比较:蒙特卡罗随机失活{.external} 和深度集成{.external}。
本教程例举了基于小型 2D 数据集的 SNGP 模型。有关使用 BERT-base 将 SNGP 应用于现实世界自然语言理解任务的示例,请参阅 SNGP-BERT 教程。有关基于各种基准数据集(例如 CIFAR-100、ImageNet、Jigsaw 恶意检测等)的 SNGP 模型(和许多其他不确定性方法)的高质量实现方式,请参阅不确定性基线{.external} 基准。
关于 SNGP
SNGP 是一种可提高深度分类器的不确定性质量,同时能够保持相似准确率和延迟水平的简单方式。给定一个深度残差网络,SNGP 即会对模型进行两项简单更改:
将谱归一化应用于隐藏的残差层。
将 Dense 输出层替换为高斯过程层。
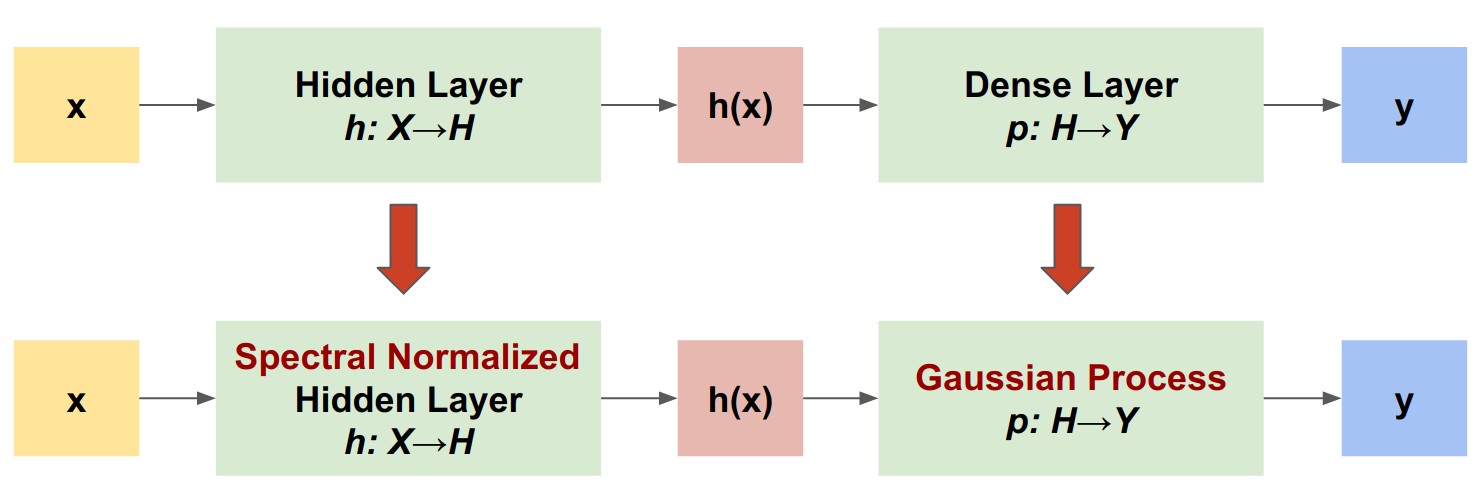
与其他不确定性方式(例如蒙特卡罗随机失活或深度集成)相比,SNGP 具有以下几项优点:
适用于各种最先进的基于残差的架构(例如 (Wide) ResNet、DenseNet 或 BERT)。
是一种单模型方法(不依赖于集合平均)。因此,SNGP 具有与单一确定性网络相似的延迟水平,并且可以轻松扩展至大型数据集,如 ImageNet{.external} 和 Jigsaw 恶意评论分类{.external}。
距离感知属性使之具有强大的域外检测性能。
这种方法的缺点为:
SNGP 的预测不确定性是使用拉普拉斯近似{.external}计算的。因此在理论上,SNGP 的后验不确定性与精确高斯过程的后验不确定性不同。
SNGP 训练需要在新周期开始时进行协方差重置步骤。这会对训练流水线额外增添些许复杂性。本教程展示了一种使用 Keras 回调实现此功能的简单方式。
安装
定义呈现宏
双月数据集
从 scikit-learn 双月数据集{.external} 创建训练数据集和评估数据集。
评估模型在整个二维输入空间上的预测行为。
要评估模型不确定性,请添加属于第三类的域外 (OOD) 数据集。该模型在训练期间从不观测这些 OOD 样本。
这里,蓝色和橙色代表正负类,红色代表 OOD 数据。能够准确量化不确定性的模型在接近训练数据时(即 接近 0 或 1)应达到较高的置信度,而在远离训练数据区域时(即 接近 0.5)则不确定性较高。
确定性模型
定义模型
从(基线)确定性模型开始:具有随机失活正则化的多层残差网络 (ResNet)。
本教程使用具有 128 个隐藏单元的六层 ResNet。
训练模型
配置训练参数以使用 SparseCategoricalCrossentropy 作为损失函数和 Adam 优化器。
以 128 为批次大小对模型训练 100 个周期。
呈现不确定性
现在,呈现确定性模型的预测。首先绘制类概率:
在此图中,黄色和紫色为这两个类的预测概率。确定性模型在利用非线性决策边界对两个已知类(蓝色和橙色)进行分类方面表现优秀。然而,它并不具备距离感知,并且会以较高的置信度将从未观测到的红色域外 (OOD) 样本分类为橙色类。
通过计算预测方差来呈现模型的不确定性:<code class="part_formula"><code class="part_formula">
在此图中,黄色表示高不确定性,紫色表示低不确定性。确定性 ResNet 的不确定性仅取决于测试样本与决策边界之间的距离。这会导致模型在超出训练域时出现置信度过度的问题。下一部分将展示 SNGP 在此数据集上的行为方式有何不同。
SNGP 模型
定义 SNGP 模型
现在,我们来实现 SNGP 模型。SNGP 组件 SpectralNormalization 和 RandomFeatureGaussianProcess 均在 tensorflow_model 的内置层中可用。
让我们更加详细地检查这两个组件。(您也可以跳转到完整 SNGP 模型部分以了解 SNGP 的实现方法。)
SpectralNormalization 封装容器
SpectralNormalization{.external} 是 Keras 层封装容器。它能够以如下方式应用于现有的 Dense 层:
谱归一化会通过将其谱范数(即 的最大特征值)朝目标值 norm_multiplier 逐渐引导来正则化隐藏权重 。
注:通常情况下,最好将 norm_multiplier 设置为小于 1 的值。但在实践中,也可以将其放宽为更大的值,以确保深度网络具有足够的表达力。
高斯过程 (GP) 层
RandomFeatureGaussianProcess{.external} 可对能够通过深度神经网络进行端到端训练的高斯过程模型实现基于随机特征的近似{.external}。从底层来看,高斯过程层实现了一个两层网络:
Here, is the input, and and are frozen weights initialized randomly from Gaussian and Uniform distributions, respectively. (Therefore, are called "random features".) is the learnable kernel weight similar to that of a Dense layer.
GP 层的主要参数包括:
units:输出 logit 的维度。num_inducing:隐藏权重 的维度 。默认值为 1024。normalize_input:是否对输入 应用层归一化。scale_random_features:是否将缩放 应用于隐藏输出。
注:对于对学习率较为敏感的深度神经网络(例如 ResNet-50 和 ResNet-110),一般建议设置 normalize_input=True 以提高训练稳定性,并设置 scale_random_features=False 以避免在通过 GP 层时学习率被意外修改。
gp_cov_momentum可以控制如何计算模型协方差。如果设置为正值(例如0.999),将使用基于动量的移动平均值更新(类似于批归一化)计算协方差矩阵。如果设置为-1,则协方差矩阵将在无动量情况下更新。
注:基于动量的更新方法可能会对批次大小较为敏感。因此,通常建议设置 gp_cov_momentum=-1 以精确计算协方差。为了使其正常工作,协方差矩阵 estimator 需要在新周期开始时重置,以避免重复计算相同的数据。对于 RandomFeatureGaussianProcess,这可以通过调用其 reset_covariance_matrix() 来实现。下一部分展示了使用 Keras 内置 API 的简单实现。
给定一个形状为 (batch_size, input_dim) 的批次输入,GP 层会返回 logits 张量(形状为 (batch_size, num_classes))用于预测;以及 covmat 张量(形状为 (batch_size, batch_size)),它是批次 logit 的后验协方差矩阵。
注:请注意,在 SNGP 模型的这种实现方式下,所有类的预测 logit 都会共享相同的协方差矩阵 ,后者描述了 与训练数据之间的距离。
理论上讲,可以扩展算法来为不同类计算不同的方差值(如原始 SNGP 论文{.external}中所介绍)。但是,这很难扩展到具有大输出空间的问题(例如使用 ImageNet 或语言建模的分类)。
给定基类 DeepResNet,即可通过修改残差网络的隐藏层和输出层来轻松实现 SNGP 模型。为了与 Keras model.fit() API 兼容,还需修改模型的 call() 方法,使其仅在训练期间输出 logits。
使用与确定性模型相同的架构。
将此回调添加到 DeepResNetSNGP 模型类。
训练模型
使用 tf.keras.model.fit 训练模型。
呈现不确定性
首先,计算预测 logit 和方差。
现在,计算后验预测概率。计算概率模型预测概率的经典方法是使用蒙特卡罗采样法,即:
其中 为样本大小, 为来自 SNGP 后验 (sngp_logits,sngp_covmat) 的随机样本。但是,这种方式对于延迟敏感型应用(例如自动驾驶或实时竞价)而言,速度可能较慢。相反,您可以使用平均场法{.external}来逼近 :
where is the SNGP variance, and is often chosen as or .
注:除了将 限定为固定值之外,您还可以将其视为超参数,并对其进行调整以优化模型的校准性能。这在深度学习不确定性文献中被称为温度缩放{.external}。
这种平均场方法以内置函数 layers.gaussian_process.mean_field_logits 形式实现:
SNGP 摘要
您现在可以将所有内容归总到一起。整个过程(训练、评估和不确定性计算)只需五行即可完成:
呈现 SNGP 模型的类概率(左)和预测不确定性(右)。
请记住,在类概率图(左)中,黄色和紫色为类概率。当接近训练数据域时,SNGP 会以较高的置信度正确分类样本(即,分配接近 0 或 1 的概率)。当远离训练数据时,SNGP 的置信度会逐渐下降,其预测概率接近 0.5,而(归一化)模型不确定性上升到 1。
将此与确定性模型的不确定性表面进行比较:
如上文所述,确定性模型不具备距离感知。它的不确定性会由测试样本与决策边界之间的距离定义。这会导致模型对域外样本(红色)产生置信度过高的预测。
与其他不确定性方式的比较
蒙特卡罗随机失活
给定具有随机失活层的经训练的神经网络,蒙特卡罗随机失活会计算平均预测概率
方法是对多个启用随机失活的前向传递求平均值 。
深度集成
深度集成是一种用于深度学习不确定性的最先进(但耗费算力)的方法。要训练深度集成,首先需要训练 个集合成员。
收集 logit 并计算平均预测概率 。
蒙特卡罗随机失活和深度集成方法都会通过降低决策边界的确定性来提高模型的不确定性能力。然而,二者均继承了确定性深度网络在缺乏距离感知方面的局限性。
总结
在本教程中,您已:
在深度分类器上实现了 SNGP 模型以提高其距离感知能力。
使用 Keras
Model.fitAPI 端到端地训练了 SNGP 模型。呈现了 SNGP 的不确定性行为。
比较了 SNGP、蒙特卡罗随机失活和深度集成模型之间的不确定性行为。
资源和延伸阅读
请参阅 SNGP-BERT 教程以查看在 BERT 模型上应用 SNGP 以实现不确定性感知型自然语言理解的示例。
请转到不确定性基线 GitHub 仓库{.external}以查看在各种基准数据集(例如,CIFAR、ImageNet、Jigsaw 恶意检测等)上实现 SNGP 模型(和许多其他不确定性方法)的方式。
如需更深入地了解 SNGP 方法,请参阅题为 Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness{.external} 的论文。