
Path: blob/master/site/zh-cn/tutorials/video/video_classification.ipynb
39043 views
Copyright 2022 The TensorFlow Authors.
 在 GitHub 上查看源代码
在 GitHub 上查看源代码使用 3D 卷积神经网络 (CNN) 进行视频分类
本教程演示了如何使用 UCF101 动作识别数据集训练一个用于视频分类的 3D 卷积神经网络。3D CNN 使用三维过滤器来执行卷积。内核能够在三个维度上滑动,而在 2D CNN 中,它可以在两个维度上滑动。此模型基于 D. Tran 等人在 A Closer Look at Spatiotemporal Convolutions for Action Recognition(2017 年)中发表的工作。在本教程中,您将完成以下任务:
构建输入流水线
使用 Keras 函数式 API 构建具有残差连接的 3D 卷积神经网络模型
训练模型
评估和测试模型
本视频分类教程是 TensorFlow 视频教程系列的第二部分。下面是其他三个教程:
加载视频数据:本教程解释了本文档中使用的大部分代码。
用于流式动作识别的 MoViNet:熟悉 TF Hub 上提供的 MoViNet 模型。
使用 MoViNet 进行视频分类的迁移学习:本教程介绍了如何使用预训练的视频分类模型,该模型是在具有 UCF-101 数据集的不同数据集上训练的。
安装
首先,安装和导入一些必要的库,包括:用于检查 ZIP 文件内容的 remotezip,用于使用进度条的 tqdm,用于处理视频文件的 OpenCV,用于执行更复杂张量运算的 einops,以及用于在 Jupyter 笔记本中嵌入数据的 tensorflow_docs。
注:使用 TensorFlow 2.10 运行本教程。TensorFlow 2.10 以上的版本可能无法成功运行。
加载并预处理视频数据
下面的隐藏单元定义了从 UCF-101 数据集下载数据切片并将其加载到 tf.data.Dataset 中的函数。可以在加载视频数据教程中详细了解特定的预处理步骤,此教程将更详细地介绍此代码。
隐藏块末尾的 FrameGenerator 类是这里最重要的实用工具。它会创建一个可以将数据馈送到 TensorFlow 数据流水线中的可迭代对象。具体来说,此类包含一个可加载视频帧及其编码标签的 Python 生成器。生成器 (__call__) 函数可产生由 frames_from_video_file 生成的帧数组以及与帧集关联的标签的独热编码向量。
创建训练集、验证集和测试集(train_ds、val_ds 和 test_ds)。
创建模型
以下 3D 卷积神经网络模型基于 D. Tran 等人的论文 A Closer Look at Spatiotemporal Convolutions for Action Recognition(2017 年)。这篇论文比较了数个版本的 3D ResNet。与标准 ResNet 一样,它们并非对具有维度 (height, width) 的单个图像进行运算,而是对视频体积 (time, height, width) 进行运算。解决这一问题的最明显方式是将每个 2D 卷积 (layers.Conv2D) 替换为 3D 卷积 (layers.Conv3D)。
本教程使用具有残差连接的 (2 + 1)D 卷积。(2 + 1)D 卷积允许对空间和时间维度进行分解,进而创建两个单独的步骤。这种方式的一个优势在于,将卷积因式分解为空间和时间维度有助于节省参数。
对于每个输出位置,3D 卷积将体积的 3D 补丁中的所有向量组合在一起,以在输出体积中创建一个向量。
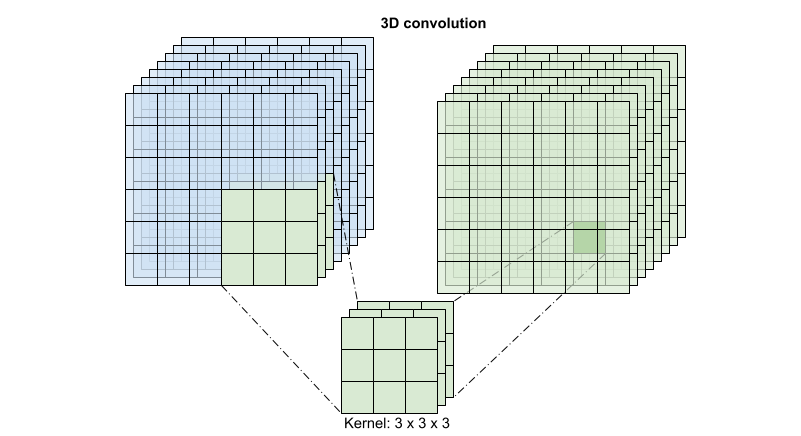
此运算需要 time * height * width * channels 个输入并产生 channels 个输出(假设输入和输出通道的数量相同。这样,内核大小为 (3 x 3 x 3) 的 3D 卷积层需要一个具有 27 * channels ** 2 个条目的权重矩阵。根据参考论文的发现,更有效且高效的方式是对卷积进行因式分解。他们提出了一个 (2+1)D 卷积来分别处理空间和时间维度,而不是用单个 3D 卷积来处理时间和空间维度。下图显示了一个 (2 + 1)D 卷积因式分解后的空间和时间卷积。
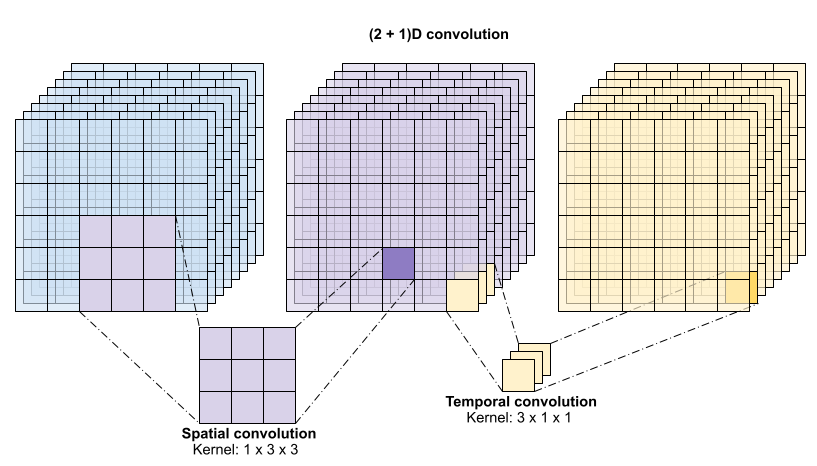
这种方式的主要优点是减少了参数数量。在 (2 + 1)D 卷积中,空间卷积接受形状为 (1, width, height) 的数据,而时间卷积接受形状为 (time, 1, 1) 的数据。例如,内核大小为 (3 x 3 x 3) 的 (2 + 1)D 卷积需要大小为 (9 * channels**2) + (3 * channels**2) 的权重矩阵,不到完整 3D 卷积的一半。本教程实现了 (2 + 1)D ResNet18,其中 ResNet 中的每个卷积都被替换为 (2+1)D 卷积。
ResNet 模型由一系列残差块组成。一个残差块有两个分支。主分支执行计算,但难以让梯度流过。残差分支绕过主计算,大部分只是将输入添加到主分支的输出中。梯度很容易流过此分支。因此,将存在从损失函数到任何残差块的主分支的简单路径。这有助于避免梯度消失的问题。
使用以下类创建残差块的主分支。与标准 ResNet 结构相比,它使用自定义的 Conv2Plus1D 层而不是 layers.Conv2D。
要将残差分支添加到主分支,它需要具有相同的大小。下面的 Project 层处理分支上通道数发生变化的情况。特别是,添加了一系列密集连接层,然后添加了归一化。
使用 add_residual_block 在模型的各层之间引入跳跃连接。
必须调整视频大小才能执行数据的下采样。特别是,对视频帧进行下采样允许模型检查帧的特定部分,以检测可能特定于某个动作的模式。通过下采样,可以丢弃非必要信息。此外,调整视频大小将允许降维,从而加快模型的处理速度。
使用 Keras 函数式 API 构建残差网络。
训练模型
对于本教程,选择 tf.keras.optimizers.Adam 优化器和 tf.keras.losses.SparseCategoricalCrossentropy 损失函数。使用 metrics 参数查看每个步骤中模型性能的准确率。
使用 Keras Model.fit 方法将模型训练 50 个周期。
注:此示例模型在较少的数据点(300 个训练样本和 100 个验证样本)上进行训练,以保持本教程具有合理的训练时间。此外,此示例模型可能需要超过一个小时来训练。
呈现结果
在训练集和验证集上创建损失和准确率的图表:
评估模型
使用 Keras Model.evaluate 获取测试数据集的损失和准确率。
注:本教程中的示例模型使用 UCF101 数据集的子集来保持合理的训练时间。通过进一步的超参数调优或更多的训练数据,可以改善准确率和损失。
要进一步呈现模型性能,请使用混淆矩阵。混淆矩阵允许评估分类模型的性能,而不仅仅是准确率。为了构建此多类分类问题的混淆矩阵,需要获得测试集中的实际值和预测值。
另外,还可以使用混淆矩阵计算每个类的准确率和召回率值。
Next steps
要详细了解如何在 TensorFlow 中处理视频数据,请查看以下教程:
加载视频数据
用于流式动作识别的 MoViNet
使用 MoViNet 进行视频分类的迁移学习