Math 480: Open Source Mathematical Software
2016-05-13
William Stein
**Lectures 21: Stats (part 3 of 3) **
Announcements:
Homework due at 6pm tonight.
Peer grading deadline extended until 6pm on Monday evening.
Next week: numpy
Today:
statsmodels
scikit-learn
working session/QA.
REMIND ME: screencast
Here's a slideshow about the "data analysis and statistics in python", or why Python is (quickly getting) better than R.
statsmodels
"Python module that allows users to explore data, estimate statistical models, and perform statistical tests."
Documentation: http://statsmodels.sourceforge.net/stable/
1. The statsmodels "Getting started" tutorial!
We download the Guerry dataset, a collection of historical data used in support of Andre-Michel Guerry’s 1833 Essay on the Moral Statistics of France. The data set is hosted online in comma-separated values format (CSV) by the Rdatasets repository. We could download the file locally and then load it using read_csv, but pandas takes care of all of this automatically for us:
| dept | Region | Department | Crime_pers | Crime_prop | Literacy | Donations | Infants | Suicides | MainCity | Wealth | Commerce | Clergy | Crime_parents | Infanticide | Donation_clergy | Lottery | Desertion | Instruction | Prostitutes | Distance | Area | Pop1831 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | E | Ain | 28870 | 15890 | 37 | 5098 | 33120 | 35039 | 2:Med | 73 | 58 | 11 | 71 | 60 | 69 | 41 | 55 | 46 | 13 | 218.372 | 5762 | 346.03 |
| 1 | 2 | N | Aisne | 26226 | 5521 | 51 | 8901 | 14572 | 12831 | 2:Med | 22 | 10 | 82 | 4 | 82 | 36 | 38 | 82 | 24 | 327 | 65.945 | 7369 | 513.00 |
| 2 | 3 | C | Allier | 26747 | 7925 | 13 | 10973 | 17044 | 114121 | 2:Med | 61 | 66 | 68 | 46 | 42 | 76 | 66 | 16 | 85 | 34 | 161.927 | 7340 | 298.26 |
| 3 | 4 | E | Basses-Alpes | 12935 | 7289 | 46 | 2733 | 23018 | 14238 | 1:Sm | 76 | 49 | 5 | 70 | 12 | 37 | 80 | 32 | 29 | 2 | 351.399 | 6925 | 155.90 |
| 4 | 5 | E | Hautes-Alpes | 17488 | 8174 | 69 | 6962 | 23076 | 16171 | 1:Sm | 83 | 65 | 10 | 22 | 23 | 64 | 79 | 35 | 7 | 1 | 320.280 | 5549 | 129.10 |
We select the variables of interest and look at the bottom 5 rows:
| Department | Lottery | Literacy | Wealth | Region | |
|---|---|---|---|---|---|
| 81 | Vienne | 40 | 25 | 68 | W |
| 82 | Haute-Vienne | 55 | 13 | 67 | C |
| 83 | Vosges | 14 | 62 | 82 | E |
| 84 | Yonne | 51 | 47 | 30 | C |
| 85 | Corse | 83 | 49 | 37 | NaN |
Notice that there is one missing observation in the Region column. We eliminate it using a DataFrame method provided by pandas:
| Department | Lottery | Literacy | Wealth | Region | |
|---|---|---|---|---|---|
| 80 | Vendee | 68 | 28 | 56 | W |
| 81 | Vienne | 40 | 25 | 68 | W |
| 82 | Haute-Vienne | 55 | 13 | 67 | C |
| 83 | Vosges | 14 | 62 | 82 | E |
| 84 | Yonne | 51 | 47 | 30 | C |
Some statistics...
Substantive motivation and model: We want to know whether literacy rates in the 86 French departments are associated with per capita wagers on the Royal Lottery in the 1820s. We need to control for the level of wealth in each department, and we also want to include a series of dummy variables on the right-hand side of our regression equation to control for unobserved heterogeneity due to regional effects. The model is estimated using ordinary least squares regression (OLS).
(WARNING: I'm not a statistician...)
Use patsy‘s to create design matrices, then use statsmodels to do an ordinary least squares fit.
statsmodels also provides graphics functions. For example, we can draw a plot of partial regression for a set of regressors by:

2. Scikit Learn: Easy Machine Learning
From their website:
Machine Learning in Python
Simple and efficient tools for data mining and data analysis
Accessible to everybody, and reusable in various contexts
Built on NumPy, SciPy, and matplotlib
Open source, commercially usable - BSD license
This "digits" thing is 1797 hand-written low-resolution numbers from the postcal code numbers on letters (zip codes)...
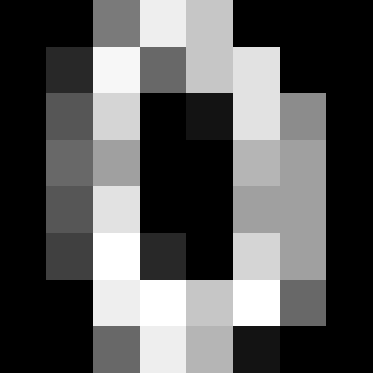
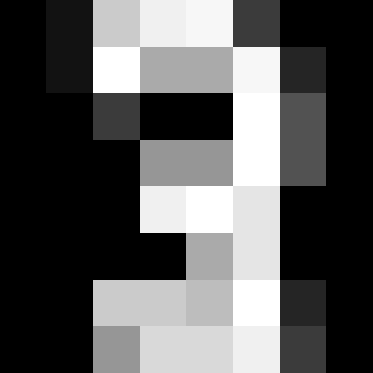
Example/goal here:
"In the case of the digits dataset, the task is to predict, given an image, which digit it represents. We are given 1797 samples of each of the 10 possible classes (the digits zero through nine) on which we fit an estimator to be able to predict the classes to which unseen samples belong."
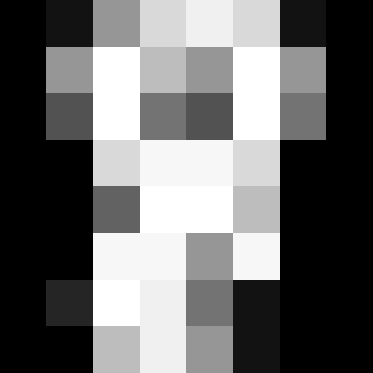
This clf is a "classifier". Right now it doesn't know anything at all about our actual data.
We teach it by passing in our data to the fit method...
"We use all the images of our dataset apart from the last one. We select this training set with the [:-1] Python syntax, which produces a new array that contains all but the last entry of digits.data:"
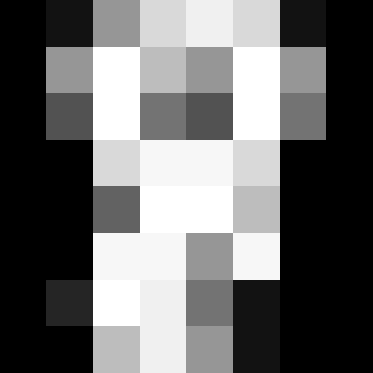
** Exercise for you right now: ** Run the prediction on all 1797 scaned values to see how many are correct.
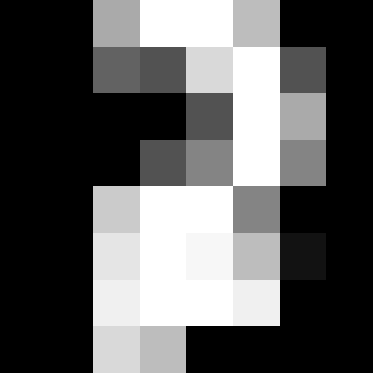
bonus
plots of low dimensional embeddings of the digits dataset:
http://scikit-learn.org/stable/auto_examples/manifold/plot_lle_digits.html