
Path: blob/main/Db2-L3-Tech-Lab/IBM_Db2_Level_3.ipynb
1928 views

Introduction
Data is the fuel that artificial intelligence (AI) engines run on. And databases often serve as the main repository for an organization's data. IBM has been a pioneer in data management technologies and advancements for decades. And a crucial part of this journey has been the invention of IBM Db2, a database built to address current data management needs, as well as provide an advantage as companies begin to incorporate AI into their workflows. Db2 databases are powered by AI to optimize and improve the data management process — AI-based features include a query optimizer that utilizes machine learning (ML), an adaptive workload manager that automatically adjusts concurrently running workloads to ensure the optimal number of queries are executed without compromising database stability, and built-in ML stored procedures that enable enterprises to learn from their data, at scale, without having to move it off-platform. Furthermore, Db2 is built for AI, ensuring users can effectively build AI models using popular programming languages like Python and R, as well as make them accessible through application programming interfaces (APIs) like representational state transfer (REST) APIs. All supported by enterprise-grade features like BLU Acceleration, massively parallel processing, and active compression, alongside robust security, highly available scalability (especially with pureScale technology), and disaster recovery.
This hands-on lab is designed to do several things:
- Introduce you to some of the basic objects you will find in almost every Db2 database, as well as show you how to create and delete them
- Show you how to create and execute some simple Structured Query Language (SQL) statements that can be used to store, modify, retrieve, and delete data in a Db2 database
- Introduce you to some advanced Db2 topics such as the Db2 Explain facility, user defined functions, and SQL procedures
- Illustrate how to build Python applications that interact with a Db2 database, regardless of whether the database is on-premises (created using IBM Db2 Community Edition) or in the Cloud (created under the Db2 "Lite" service on IBM Cloud).
Working with Jupyter Notebook
As you can see, this hands-on lab is provided in the form of a Jupyter Notebook. If you are unfamiliar with this technology, a Jupyter Notebook is an open source web application that enables users to create and share documents that contain narrative text, live code, equations, and rich outputs such as graphical visualizations. (Jupyter Notebook is maintained by Project Jupyter.) The name Jupyter comes from the core programming languages Jupyter Notebooks support: Julia, Python, and R. Jupyter ships with the IPython kernel, which enables users to write programs in Python, but there are currently over 100 other kernels that Jupyter Notebook supports.
The Jupyter Notebook framework contains several menu items and icons that enable users to interact with a notebook. The menu runs along the top of a Notebook just like menus do in other applications; the icons (buttons) are found just below the menu items. This introduction doesn't go into detail about each option available with every menu item. Instead, it will focus on just the two icons you will need to be familiar with to perform the exercises in this lab — these icons/buttons are emphasized in the following illustration:

-
The
 icon (button) is used to save any changes you make to the notebook. Ctrl+s (Command+s on Mac) performs the same function.
icon (button) is used to save any changes you make to the notebook. Ctrl+s (Command+s on Mac) performs the same function. - The
 icon (button) is used to execute the code — in our case Python — shown in a "Code" cell. Shift+Enter performs the same function.
icon (button) is used to execute the code — in our case Python — shown in a "Code" cell. Shift+Enter performs the same function.
If there are multiple code cells in a Notebook (as there are in this Notebook) and you run the cells in order, imports (external modules that are loaded into an application for use) and variables can be shared across cells. This makes it easy to separate out code into logical chunks without needing to reimport libraries or recreate variables or functions in each cell. (That being said, you will see some variables get recreated in each code cell in this lab — that's done to both reset the variable and to draw your attention to the variables that are used for each operation.)
When you select a code cell, you will notice that there are some square braces () beside the word In located at the top and just to the left of the cell. As you work your way through the Notebook, the square braces will be filled with a number that indicates the order in which each cell was ran. For example, if you run the first code cell found at the top of a Notebook, the square braces will be filled with the number 1. If you run the next code cell found after it, the square braces beside that cell will be filled with the number 2, and so on. While a code cell is being executed, the square braces will be filled with an asterisk (*).
How this lab is organized
The exercises found in this hands-on lab are organized as follows:
- Section 1. Prepare the lab environment
- Step 1. Set up the Jupyter Notebook environment
- Step 2. Create a function that uses APIs in the ibm_db driver to execute SQL queries and retrieve/display query results
- Step 3. Assign values to application variables that will be used to establish a database connection
- Section 2. IBM Db2 basics
- Step 1. Establish a database connection
- Step 2. Query the database's system catalog
- Step 3. Create a table named EMPLOYEE
- Step 4. Insert a record into the EMPLOYEE table
- Step 5. Add additional records to the EMPLOYEE table using a prepared INSERT statement with parameter markers
- Step 6. Create a second table named DEPARTMENT and populate it
- Step 7. Create a view named EMP_DEPT
- Step 8. Change a record in the EMPLOYEE table
- Step 9. Remove records from the EMPLOYEE table
- Step 10. Create the tables that are used by the Db2 Explain facility ( Optional )
- Step 11. Collect Explain data for a simple query ( Optional )
- Step 12. Create an index named EMP_IDX
- Step 13. Generate Explain data for the simple query again to see if the new index improves query performance ( Optional )
- Step 14. Roll back and commit a transaction
- Section 3. Advanced topics
- Step 1. Create two user defined functions
- Step 2: Invoke an SQL Scalar and an SQL Table user defined function
- Step 3. Create an SQL procedure
- Step 4: Invoke an SQL procedure
- Section 4. Lab environment clean up
- Step 1. Remove the tables used by the Db2 Explain facility ( Optional )
- Step 2: Query the system catalog to see all the user-defined objects created in this lab
- Step 3. Remove all user-defined objects created earlier from the database
- Step 4. Query the system catalog again to confirm that all user-defined objects created in this lab have been deleted
- Step 5. Terminate the database connection
| [ ] | : | Parameters or items shown inside brackets are required and must be provided. |
| < > | : | Parameters or items shown inside angle brackets are optional and do not have to be provided. |
| | | : | Vertical bars indicate that one (and only one) item in the list of items presented can be specified. |
| , ... | : | A comma followed by three periods (ellipsis) indicate that multiple instances of the preceding parameter or item can be included in the Db2 command or SQL statement. |
The following example illustrates each of these conventions:
Example:
REFRESH TABLE [ TableName , ... ]
< INCREMENTAL | NON INCREMENTAL >
In this example, you must supply at least one TableName value, as the brackets ( ) indicate, and you can provide more than one TableName value, as the comma and ellipsis ( , ... ) characters that follow the TableName parameter suggest. INCREMENTAL and NON INCREMENTAL are optional, as the angle brackets ( < > ) signify, and you can specify either one or the other, but not both, as the vertical bar ( | ) indicates.
Using IBM Db2 Community Edition with this hands-on lab
While this hands-on lab is set up to be ran with the Db2 "Lite" service on IBM Cloud, this Jupyter Notebook can be used with IBM Db2 Community Edition as well. IBM Db2 Community Edition is a special no-charge, full featured version of Db2 that enables data professionals to develop and deploy applications using any of the features and functionality found in in the latest release of IBM Db2. There are no limits on how long IBM Db2 Community Edition can be used, and unlike with the Db2 "Lite" service on IBM Cloud, there are no limits on the size of databases that can be created. However, there are limits on the number of cores and amount of memory supported: IBM Db2 Community Edition can be used with up to four processor cores and no more than 16 gigabytes (GB) of random access memory (RAM). One advantage of using IBM Db2 Community Edition for this lab is that the exercises labeled "Optional " can be executed — with the Db2 "Lite" service on IBM Cloud, the code for these exercises can be examined, but the code cells cannot be run.
To download a copy of IBM Db2 Community Edition, simply go to the IBM Db2 web site (which can be found here: IBM Db2 Database) and click on the “Try it on premises →” button shown on the page. After completing and submitting the form presented, you will be re-directed to the IBM Db2 Download Center web site. Once there, select the “Download” link that corresponds to the operating system you plan to install IBM Db2 Community Edition on. When the file has finished downloading, refer to the IBM Db2 documentation for instructions on how to install and configure the IBM Db2 Community Edition software. (Instructions for installing Db2 Version 11.5 can be found here: Db2 servers and IBM data server clients. A Bash shell script that streamlines and automates the installation process on Ubuntu Linux is available here: db2_env_setup.sh — right-click on the link and select "Save Link As..." to download this file.)
Section 1. Prepare the lab environment
Step 1. Set up the Jupyter Notebook environment
Overview:
Before you can begin interacting with an IBM Db2 database using Python or Jupyter Notebook, there are some basic steps you must perform. These steps include:
- Downloading and installing the ibm_db Python database interface driver for IBM Db2, IBM Informix, IBM Db2 for iSeries(AS400) and IBM Db2 for z/OS servers.
- Loading (importing) the ibm_db driver into the Python application or Jupyter Notebook.
- Loading any additional external Python modules needed into the Python application or Jupyter Notebook.
- Defining any variables that will be used to supply information to, or obtain infromation from application programming interfaces (APIs) in the ibm_db driver. (These APIs are used to do things like establish a connection to a database, submit a query for execution, retreive query results, and so forth.)
Execute the code:
The code in the next "cell" performs all but the last of the tasks just identified — the task of defining variables will be performed, when necessary, throughout the remaining exercises in this lab.
- Select the code cell below and carefully read through the comments (i.e., the text that begins with a # character). This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 2: Create a function that uses APIs in the ibm_db driver to execute SQL queries and retreive/display query results
Overview:
Structured Query Language (SQL) is a standardized language that is used to work with database objects and the data they contain. Using SQL, it's possible to define, alter, and delete database objects, as well as add data to, change data in, and retrieve or remove data from any objects created. Because SQL is non-procedural by design, it is not considered an actual programming language even though, like other programming languages, it has a defined syntax and its own set of language elements. Consequently, applications that utilize SQL are are typically built by combining the decision and sequence control of a high-level programming language — in our case, Python — with the data storage, manipulation, and retrieval capabilities SQL provides.
SQL statements are frequently categorized according to the function they're designed to perform:
- Embedded SQL Application Construct statements: Used for the sole purpose of constructing embedded SQL applications. (Applications written with the C programming language frequently use these statements.)
- Data Control Language (DCL) statements: Used to grant and revoke authorities and privileges needed for Db2 instance management and data access.
- Data Definition Language (DDL) statements: Used to create, alter, and delete database objects.
- Data Manipulation Language (DML) statements: Used to store data in, modify data in, retrieve data from, and remove data from select database objects.
Because many of the exercises found in this lab focus on constructing and executing DDL and DML statements, the database used will be queried often to ensure that operations desired are performed as expected. Rather than repeat the Python code needed to execute a query, retreive the results, and display the information obtained every time a query is executed, the code in the following cell will encapsulate this work in a Python function that can be called whenever a query needs to be executed.
With Python and Jupyter Notebook, application programming interfaces (APIs) in the ibm_db Python database interface driver are used to submit SQL statements to a Db2 database for processing, as well as retreive results. The APIs used in the code in the following cell include:
| • | ibm_db.exec_immediate( ) | : | Used to prepare and execute an SQL statement, using values supplied for parameter markers that were coded in the statement (if there are any), immediately. |
| • | ibm_db.stmt_errormsg( ) | : | Used to return an SQLCODE and corresponding error message that explains why an attempt to return an IBM_DBStatement object from an ibm_db.prepare( ), ibm_db.exec_immediate( ), or ibm_db.callproc( ) API call was unsuccessful; can also be used to return an SQLCODE and error message that identifies why the last operation using a IBM_DBStatement object failed. |
| • | ibm_db.fetch_tuple( ) | : | Used to retrieve a row (record) from a result set and copy its data to a Python tuple. Depending on how it is called, it can advance a cursor to the next row in a result set and copy the data for that row into a tuple. Or, it can be used to retrieve the data for a specific row — provided a keyset driven, dynamic, or static cursor is used to traverse the result set. In either case, the value for the first column in the row will be stored in the first position of the tuple (index position 0), the second column will be stored in the second position (index position 1) and so on. . |
You can learn more about the APIs that are available with the ibm_db Python interface driver here: IBM Db2-Python and here: ibmdb/python-ibmdb APIs.
Execute the code:
- Select the code cell below and carefully read through the comments. This will help you understand the operations the function performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 3. Assign values to application variables that will be used to establish a database connection
Overview:
Before operations can be performed against an IBM Db2 database, a connection to the database must first be established. To do this, you need information about the database environment such as the database's name or alias, the host name or IP address of the database server, and the port number Db2 uses for TCP/IP communications. You also need appropriate authorization credentials, which typically consist of a user or authentication ID and a corresponding password. Instructions on how to obtain this information are provided in the main guide for this lab.
Execute the code:
Once you have collected the information needed, perform these steps to assign it to the application variables that will be used later to establish a database connection:
- Select the appropriate code cell below and assign values to the
dbName,hostName,portNum,userID, andpassWordapplication variables. If the database you are using is provided through the Db2 "Lite" service on IBM Cloud, modify the code in the cell immediately below the heading Step 3a: Connect to a remote, Db2 on Cloud database. On the other hand, if you are using a local database that was created with IBM Db2 Community Edition (or some other Db2 Edition), modify the code in the the cell immediately below the heading Step 3b: Connect to a local, on-premises Db2 database. -
Click on thebutton or press Ctrl+s (or command+s on Mac) to save your changes.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Whenever new values are assigned to the variables in the cell below, the code must be saved and re-executed. Otherwise, the code in the code cells that follow may not execute correctly.
Step 3a: Connect to a remote, Db2 on Cloud database
Step 3b: Connect to a local, on-premises Db2 database
Section 2. IBM Db2 basics
Step 1: Establish a database connection
Overview:
As mentioned earlier, before anything can be done with a Db2 database, a connection to the database must first be established. With Python and Jupyter Notebook, the ibm_db.connect( ) API is typically used to perform this task. This API utilizes a connection string that has the following format:
DRIVER={IBM DB2 ODBC DRIVER};ATTACH=connType;DATABASE=dbName;HOSTNAME=hostName;PORT=portNum;PROTOCOL=TCPIP;SECURITY=SSL;UID=userName;PWD=passWord
where:
| • | connType | : | Specifies whether a connection is to be made to Db2 server (TRUE) or a Db2 database (FALSE). |
| • | dbName | : | The name of the Db2 server or database the connection is to be made to. |
| • | hostName | : | The host name or IP address of the Db2 server — as it is known to the TCP/IP network — the connection is to be made to. |
| • | portNum | : | The port number that receives Db2 connections on the server the connection is to be made to. |
| • | userName | : | The user name/authorization ID that is to be used for authentication when the connection is established. |
| • | passWord | : | The password that corresponds to the user name/authorization ID specified in the userName parameter. |
In addition, if Secure Sockets Layer (SSL) communications is not being used to establish a connection to a local Db2 database, the "SECURITY=SSL" clause should not be included in the connection string used.
Execute the code:
The code in the next cell builds a connection string in the format just described, using the values assigned to application variables earlier. It then attempts to establish a connection to the Db2 database specified.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 2: Query the database's system catalog
Overview:
When an IBM Db2 database is first created, it only contains a system catalog, which is a set of special tables and views that contain definitions of database objects, statistical information about the objects themselves, and information about the type of access users have to those objects. (Db2 automatically updates these tables and views whenever the RUNSTATS command or select SQL statements are executed — You can learn more about the system catalog views here: Catalog views.) All other data objects must be explicitly defined.
You can obtain a list of the tables that have been defined in a database — including those tables that are part of the system catalog — by querying a system catalog view named SYSCAT.TABLES. (We will take a closer look at tables in the next step.)
Execute the code:
The code in the next cell queries the SYSCAT.TABLES view and returns only a list of user-defined tables — if this is your first attempt at performing this lab, there shouldn't be any user-defined tables in the database.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 3: Create a table named EMPLOYEE
Overview:
A table is an object in a Db2 database that serves as the main repository for data. Tables present data as a collection of unordered rows with a fixed number of columns. Each column contains values of the same data type, and each row contains a set of values for one or more of the columns available. The storage representation of a row is called a record, the storage representation of a column is called a field, and each intersection of a row and column is referred to as a value (or cell). The following illustration highlights each of these components:

Figure 1: Structure of a table
Tables are created by executing the CREATE TABLE SQL statement. In its simplest form, the syntax for this statement looks like this:
CREATE TABLE [ TableName ] ( [ Element ] , ... )
< ORGANIZE BY [ ROW | COLUMN ] >
where:
| • | TableName | : | Identifies the name to assign to the table that is to be created. |
| • | Element | : | Identifies one or more columns, UNIQUE constraints, CHECK constraints, referential constraints, informational constraints, and/or a primary key constraint to include in the table definition. |
The syntax used to define each element varies according to the element specified — the basic syntax used to define a column element (which is the most common type of element used) is:
[ ColumnName ] [ DataType ]
< NOT NULL >
< WITH DEFAULT < [ DefaultValue ] | NULL > >
< UniqueConstraint >
< CheckConstraint >
< RIConstraint >
where:
| • | ColumnName | : | Identifies the name to assign to the column; the name specified must be unique. |
| • | DataType | : | Identifies the data type to assign to the column; the data type determines the kind of data values that can be stored in the column. (You can learn more about the data types available with Db2 here: Data types) |
| • | DefaultValue | : | Identifies the default value to provide for the column if no value for the column is supplied when a new record is added to the table. |
| • | UniqueConstraint | : | Identifies a UNIQUE or primary key constraint that is to be associated with the column. A UNIQUE constraint can be used to ensure that values assigned to one or more columns of a table are never duplicated; a primary key is a special form of a UNIQUE constraint that uniquely defines the characteristics of each table row. (You can learn more about UNIQUE and primary key constraints here: Types of constraints) |
| • | CheckConstraint | : | Identifies a CHECK constraint that is to be associated with the column. A CHECK constraint can be used to ensure that a particular column in a table is never assigned an unacceptable value. (You can learn more about check constraints here: Types of constraints) |
| • | RIConstraint | : | Identifies a referential integrity constraint that is to be associated with the column. Referential integrity constraints (also known as referential constraints and foreign key constraints) can be used to define required relationships between select columns and tables. (You can learn more about referential integrity constraints here: Types of constraints) |
Therefore, to create a table named EMPLOYEES that contains three columns, one of which is named EMPID that will be used to store integer data, one that is named NAME that can contain up to 30 characters, and one that is named DEPT that will be used to store fixed-length character string data that is three characters long, you would execute a CREATE TABLE statement that looks like this:
CREATE TABLE employees (empid INTEGER, name VARCHAR(30), dept CHAR(3))
Execute the code:
The code in the next cell builds a CREATE TABLE statement and then executes it to create a table named EMPLOYEE. (This table will be used by other exercises in this lab.) It then queries the system catalog to verify that the EMPLOYEE table exists.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 4: Insert a record into the EMPLOYEE table
Overview:
When a table is first created, it is nothing more than a definition of how a set of data values are to be stored — no data is actually stored in it. But once created, a table can be populated in a variety of ways. For example, it can be bulk-loaded using Db2 utilities like Import, Ingest, and Load. Or, data can be added to it, one record (row) at a time, using the INSERT SQL statement.
The basic syntax for the INSERT statement looks like this:
INSERT INTO [ TableName | ViewName ]
< ( [ ColumnName ] , ... ) >
VALUES ( [ Value | NULL | DEFAULT ] , ... )
where:
| • | TableName | : | Identifies, by name, the table data is to be added to; this can be any type of table except a system catalog table or a system-maintained materialized query table (MQT). |
| • | ViewName | : | Identifies, by name, the view data is to be added to; this can be any type of view except a system catalog view or a read-only view. |
| • | ColumnName | : | Identifies, by name, one or more columns that data values are to be assigned to; each column name provided must identify an existing column in the table or view specified. |
| • | Value | : | Identifies one or more data values that are to be added to the table or view specified. |
Thus, to add a record to a table named DEPARTMENT that was created using a CREATE TABLE statement that looked like this:
CREATE TABLE department (deptno CHAR(3), deptname CHAR(20), mgrid INTEGER)
You might execute an INSERT statement that looks like this:
INSERT INTO department (deptno, deptname, mgrid) VALUES ('A01', 'ADMINISTRATION', 1000)
It is important to note that the number of values provided in the VALUES clause must equal the number of column names identified in the column name list. The values provided will be assigned to columns in the order in which they appear — in other words, the first value listed will be assigned to the first column identified, the second value will be assigned to the second column identified, and so on. In addition, each value supplied must be compatible with the data type of the column it is being assigned to. (For example, a character string value can only be assigned to a column that has character string data type.)
If values are provided for every column found in the table, the column name list can be omitted. In this case, the first value provided is assigned to the first column in the table, the second value is assigned to the second column, and so on. Thus, the record that was added to the DEPARTMENT table in the previous example could just as easily have been added by executing an INSERT statement that looks like this:
INSERT INTO department VALUES ('A01', 'ADMINISTRATION', 1000)
Along with literal values, two special tokens can also be used to assign values to individual columns. The first token, DEFAULT, is used to assign a system- or user-supplied value to a column that was defined as having a default constraint when the table was created. The second, the NULL token, is used to assign a NULL value to any nullable column — that is, any column that was not defined as having a NOT NULL constraint.
Therefore, you could add a record that contains a NULL value for the MGRID column to the DEPARTMENT table defined earlier by executing an INSERT statement that looks like this:
INSERT INTO department VALUES ('A01', 'ADMINISTRATION', NULL)
Execute the code:
The code in the next cell drops (removes) the table named EMPLOYEE that was created earlier.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 5: Add additional records to the EMPLOYEE table using a prepared INSERT statement with parameter markers
Overview:
With Python and Jupyter Notebook (as well as many other programming languages), there are two ways in which SQL statements can be executed:
- Prepare and then execute: This approach separates the preparation of an SQL statement from its actual execution and is typically used when a statement is to be executed repeatedly (often with different values being supplied for place holders in the statement with each execution). This method is also used when an application needs to know information about the columns that will exist in the result set produced by the statement, in advance. The ibm_db.prepare( ) and ibm_db.execute( ) application programming interfaces (APIs) in the ibm_db library are used to process SQL statements in this manner.
- Execute immediately: This approach combines the preparation and execution of an SQL statement into a single step and is typically used when a statement only needs to be executed once. The ibm_db.exec_immediate( ) API in the ibm_db library is used to process SQL statements in this manner. (This has been the approach used in the lab exercises thus far.)
Execute the code:
The code in the next cell builds an INSERT statement with parameter markers, prepares it, and then executes it repeatedly to add several different records to the EMPLOYEE table created earlier. It then queries the table to verify the records were successfully added.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 6: Create a second table named DEPARTMENT and populate it
Overview:
The next exercise uses both the EMPLOYEE table that was just populated and a second table named DEPARTMENT. Therefore, a table named DEPARTMENT needs to be created and populated.
Execute the code:
The code in the next cell creates a table named DEPARTMENT and uses an INSERT statement with parameter markers to populate it. It then queries the table to verify the table exists and that 6 records have been added to it.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 7: Create a view named EMP_DEPT
Overview:
A view is a database object that is used to provide an alternative way of describing and displaying data stored in one or more tables. As with tables, views can be thought of as having columns and rows; unlike tables, views do not contain data. Instead, a view is essentially a named specification of a result table that is populated whenever the view is referenced. (Each time a view is referenced, a query is executed, and the results are retrieved from one or more underlying tables and returned in a table-like format.) The following illustration shows how a simple view that presents data from two different tables might look:
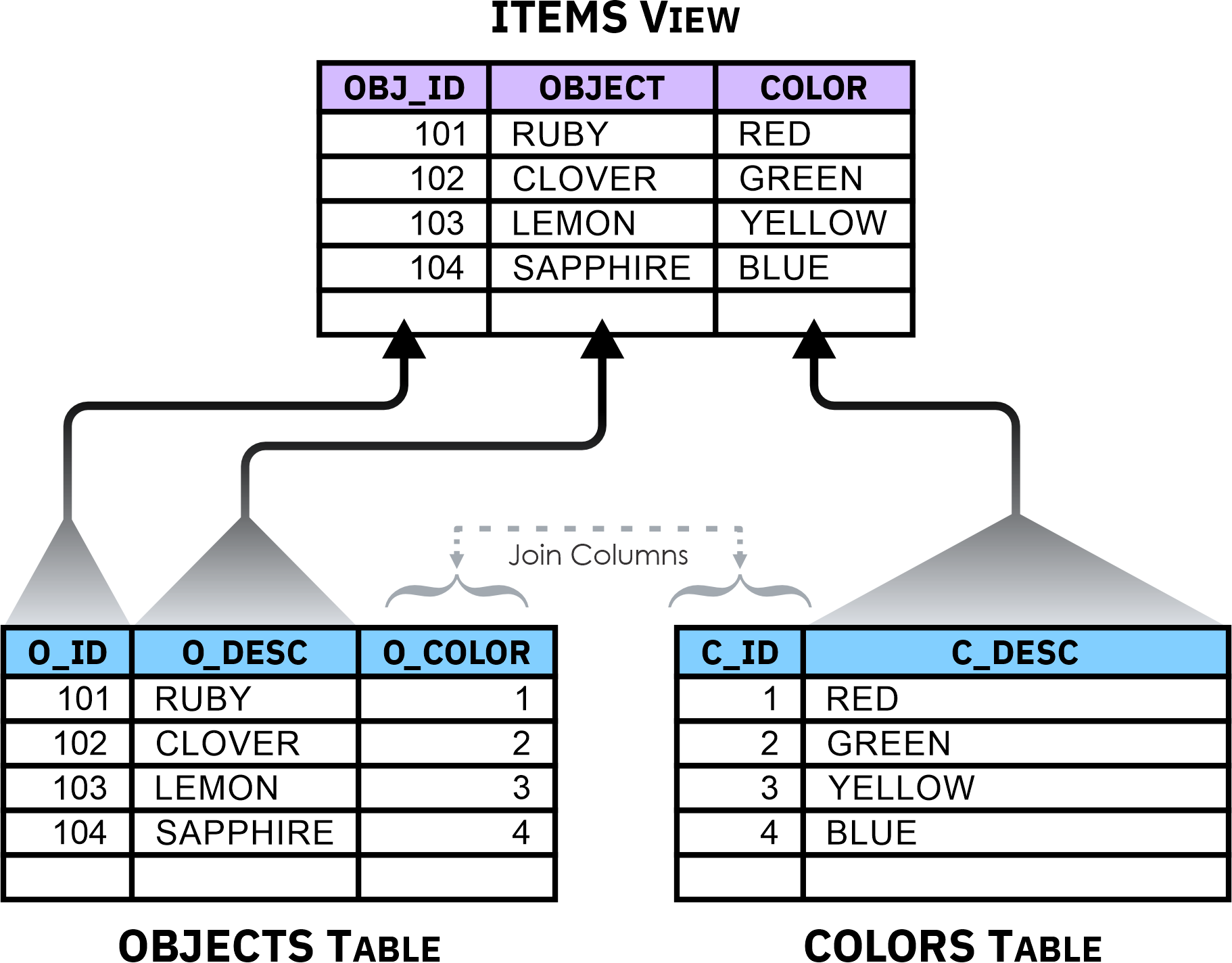
Figure 2: A view that presents data stored in two different tables
Because views look similar to tables, in most cases they can be referenced in the same way that tables can be referenced. That is, they can be the source of queries as well as the target of INSERT, UPDATE, and DELETE operations. (We will take a closer look at the UPDATE and DELETE statements shortly.) When a view is the target of such an operation, the query that was used to define the view is executed and the operation is performed on the results — the operation itself is actually executed against the base table(s) the view is derived from. (If a view is derived from other views, the operation cascades down through all applicable views until it reaches the appropriate table/tables.)
It is important to note that a single base table can serve as the source of multiple views; the SQL query provided as part of a view’s definition determines the data that is to be presented when the view is referenced. Because of this, views are sometimes used to control access to sensitive data. For example, if a table contains information about every employee who works for a company (including sensitive information like bank account numbers used for direct deposit), managers might access this table via a view that allows them to see only non-sensitive information about employees who report directly to them. Similarly, Human Resources personnel could be given access to the table by means of a view that lets them see only the information needed to generate employee paychecks. Because each set of users are given access to data through different views, they each see different presentations of data that resides in the same table.
Views are created by executing the CREATE VIEW SQL statement. In its simplest form, the syntax for this statement looks like this:
CREATE VIEW [ ViewName ]
< ( [ ColumnName ] , ... ) >
AS [ SELECTStmnt ]
where:
| • | ViewName | : | Identifies the name to assign to the view that is to be created. |
| • | ColumnName | : | Identifies, by name, one or more columns that are to be included in the view — if a list of column names is provided, the number of column names supplied must match the number of columns that will be returned by the SELECT statement used to create the view; otherwise, if a list of column names is not provided, the view will inherit the names assigned to the columns returned by the SELECT statement used. |
| • | SELECTStmnt | : | Identifies a SELECT statement that, when executed, will produce the data values that are to be used to populate the view (by retrieving them from other tables and/or views). |
Therefore, to create a view named LARGE_DEPTS that references three specific columns found in a table named DEPARTMENT, you might execute a CREATE VIEW statement that looks something like this:
CREATE VIEW large_depts AS SELECT (dept_no, dept_name, dept_size) FROM department WHERE dept_size > 25
The resulting view will contain department number (DEPT_NO), department name (DEPT_NAME), and department size (DEPT_SIZE) information for every department that has more than 25 people assigned to it.
Execute the code:
The code in the next cell builds a CREATE VIEW statement that references the EMPLOYEE and DEPARTMENT tables created earlier. It then executes the statement to create a view named EMP_DEPT. Next, it queries the system catalog to verify that the EMP_DEPT view exists. Finally, it executes a query that uses the EMP_DEPT view as a data source and displays the records retrieved.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 8: Change a record in the EMPLOYEE table
Overview:
Data in a database is rarely static. Over time, the need to change or remove one or more values stored in a table can, and will, arise. This is where the UPDATE statement comes into play — once a table has been created and populated, any of the data values stored in it can be modified by executing this statement. The basic syntax for the UPDATE statement is:
UPDATE [ TableName | ViewName]
SET [ ColumnName ] = [ Value | NULL | DEFAULT] , ... ]
< WHERE [Condition] >
or
UPDATE [ TableName | ViewName ]
SET ( [ColumnName] , ... ) =
( [Value | NULL | DEFAULT] , ... )
< WHERE [ Condition ] >
where:
| • | TableName | : | Identifies, by name, the table that contains the data that is to be modified; this can be any type of table except a system catalog table or a system-maintained materialized query table (MQT). |
| • | ViewName | : | Identifies, by name, the view data that contains the data that is to be modified; this can be any type of view except a system catalog view or a read-only view. |
| • | ColumnName | : | Identifies, by name, one or more columns that contain data that is to be modified; each column name provided must identify an existing column in the table or view specified. |
| • | Value | : | Identifies one or more data values that are to be used to replace existing values for the ColumnName(s) specified. |
| • | Condition | : | Identifies the search criterion, in the form of a WHERE clause, that is to be used to locate one or more specific rows whose data values are to be modified. |
Thus, to change the records stored in the EMPLOYEE table created earlier such that the SALARY of every employee with the title of ANALYST is increased by 6%, you would execute an UPDATE statement that looks like this:
UPDATE employee SET salary = salary * 1.06 WHERE title = 'ANALYST'
In addition to providing a way to change existing data values, the UPDATE statement can also be used to remove data stored in one or more columns that are nullable (by changing the existing data value to NULL). For example, to delete the values assigned to the DEPT column of every record found in the EMPLOYEE table created earlier, you could execute an UPDATE statement that looks like this:
UPDATE employee SET dept = NULL
Execute the code:
The code in the next cell retrieves and displays a record from the EMPLOYEE table created earlier, modifies the record by executing an UPDATE statement, and then retrieves and displays the record again to verify that the changes desired were made.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 9: Remove records from the EMPLOYEE table
Overview:
While the UPDATE statement can be used to remove values from individual columns (by replacing those values with NULL), it cannot be used to remove records. To remove one or more records from a table or view, the DELETE statement must be used instead. The basic syntax for this statement is:
DELETE FROM [ TableName | ViewName ]
< WHERE [ Condition ] >
where:
| • | TableName | : | Identifies, by name, the table that contains the data that is to be deleted; this can be any type of table except a system catalog table or a system-maintained materialized query table (MQT). |
| • | ViewName | : | Identifies, by name, the view data that contains the data that is to be deleted; this can be any type of view except a system catalog view or a read-only view. |
| • | Condition | : | Identifies the search criterion, in the form of a WHERE clause, that is to be used to locate one or more specific rows whose data values are to be deleted. |
Thus, to remove records stored in the EMPLOYEE table created earlier that are associated with employees who were hired before January 1, 2015, you would execute a DELETE statement that looks like this:
DELETE FROM employee WHERE hiredate < '12/31/2014'
Execute the code:
The code in the next cell retrieves and displays all of the records stored in the EMPLOYEE table created earlier, deletes some of these records by executing a DELETE statement, and then retrieves and displays the records again to verify the appropriate records were deleted.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 10: Create the tables that are used by the Db2 EXPLAIN facility
Overview:
When an SQL or XQuery statement is submitted to Db2 for processing, Db2's cost-based query optimizer analyzes it and generates several execution plans (known as access plans) that could potentially be used to perform the desired operation. It then estimates the execution cost of each plan and chooses the access plan that has the lowest anticipated cost.
If a static SQL or XQuery statement is embedded in an application, the optimal access plan is chosen at precompile time (or at bind time if deferred binding is used), and an executable form of this plan is stored in the system catalog as an object known as a package. If however, a dynamic statement is constructed at application run time (which is the case with all of the SQL statements used in this lab), access plans are generated when the statement is prepared for execution and the access plan chosen is stored in memory, temporarily (in what is known as the global package cache).
While Db2 provides several monitoring tools that can be used to obtain information about how well (or how poorly) some SQL operations perform, these tools cannot be used to examine the access plans that were chosen by the Db2 query optimizer. Enter the Db2 Explain facility. The Db2 Explain facility enables users to capture and display detailed information about the access plan that was chosen for a particular SQL or XQuery statement, together with performance information that can be used to identify poorly written statements and/or weaknesses in a database's design. More specifically, Explain data helps users understand exactly how Db2 accesses tables and indexes to get to data. (We will take a closer look at indexes a little shortly.)
Before the Db2 Explain facility can be utilized, a special set of tables known as Explain tables must first be created. Typically, Explain tables are created in "development" databases to aid in application design, but not in "production" databases, where application code remains fairly static. Consequently, Explain tables are not created with the system catalog tables and views during the database creation process. Instead, these tables must be created manually in the database that Explain operations will be performed against. Fortunately, the process of creating Explain tables is fairly straightforward; one way is by calling the SYSPROC.SYSINSTALLOBJECTS( ) stored procedure. (We will take a closer look at stored procedures a little later.)
The SYSPROC.SYSINSTALLOBJECTS( ) procedure is used to create or drop the database objects that are required by a specific Db2 tool. The SQL syntax used to execute this procedure is:
CALL SYSPROC.SYSINSTALLOBJECTS ( [ ToolName ], [ Action ], [ TablespaceName ], [ SchemaName ] )
where:
| • | ToolName | : | Identifies the name of the tool that database objects are to be created or deleted for. Valid values include:
|
| • | Action | : | Specifies the action that is to be taken with the required objects. Valid values include:
|
| • | TablespaceName | : | Identifies, by name, the table space in which the database objects are to be created. (In most cases, the table space named SYSTOOLSPACE is used). |
| • | SchemaName | : | Identifies, by name, the schema in which the database objects are to be created. (In most cases, the schema name SYSTOOLS is used.) |
Thus, to create the database objects required for the Explain facility (i.e., the Explain tables) using the default table space and schema, you would execute an SQL statement that looks like this:
CALL SYSPROC.SYSINSTALLOBJECTS ('EXPLAIN', 'C', CAST (NULL AS VARCHAR(128)), CAST (NULL AS VARCHAR(128)))
Execute the code:
The code in the next cell creates the Explain tables by calling the SYSPROC.SYSINSTALLOBJECTS( ) stored procedure. It then queries the system catalog to verify that the Explain tables were successfully created.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
If you attempt to perform this step with a Db2 On Cloud database, IT WILL FAIL!
Step 11: Collect Explain data for a simple query
Overview:
The Explain facility consists of several different tools, and not all tools require the same type of data. As a result, two different types of Explain data can be collected:
- Comprehensive Explain data: Consists of detailed information about a specific SQL or XQuery statement access plan, such as:
- The sequence of operations that were used to process the query
- Cost information
- Query predicates and selectivity estimates for each predicate
- Statistics for all objects that were referenced in the SQL or XQuery statement at the time the explain information was captured
- Values for host variables, parameter markers, or special registers that were used to re-optimize the SQL or XQuery statement
- Explain snapshot data: Contains the current internal representation of an SQL or XQuery statement, along with any related information. This information is stored in the SNAPSHOT column of the EXPLAIN_STATEMENT Explain table.
This information is stored across many of the Explain tables available.
One way to collect both comprehensive Explain information and Explain snapshot data for a single, dynamic SQL or XQuery statement is by executing the EXPLAIN SQL statement. The basic syntax for this statement is:
EXPLAIN [ ALL | PLAN | PLAN SECTION ]
< [ FOR | WITH ] SNAPSHOT >
FOR < XQUERY > [ ExplainableStmt ]
where:
| • | ExplainableStmt | : | Identifies the "explainable" SQL or XQuery statement that comprehensive Explain and/or Explain snapshot data is to be collected for. An explainable statement can be either be a valid XQuery statement or one of the following SQL statements:
|
If the FOR SNAPSHOT option is used, only Explain snapshot information will be collected for the SQL or XQuery statement specified. If the WITH SNAPSHOT option is used instead, both comprehensive Explain data and Explain snapshot information will be collected for the SQL or XQuery statement specified. And if neither option is specified, only comprehensive Explain data will be collected — Explain snapshot data is not captured. If the XQUERY option is specified, it is implied that the statement provided for the ExplainableStmt parameter is an XQuery statement. Otherwise, it is assumed that the statement provided is one of the explainable SQL statements supported.
Thus, if you wanted to collect just comprehensive Explain data for the SQL statement SELECT * FROM department, you could execute an EXPLAIN statement that looks like this:
EXPLAIN ALL FOR SELECT * FROM department
On the other hand, if you wanted to collect only Explain snapshot data for the same SQL statement, you would execute an EXPLAIN statement that looks more like this:
EXPLAIN ALL FOR SNAPSHOT FOR SELECT * FROM department
And finally, if you wanted to collect both comprehensive Explain data and Explain snapshot information for the same SQL statement (SELECT * FROM department), you would execute an EXPLAIN statement that looks like this:
EXPLAIN ALL WITH SNAPSHOT FOR SELECT * FROM department
It is important to note that the EXPLAIN statement does NOT actually execute the SQL statement specified, nor does it display the Explain information collected — you must use other Explain facility tools or query the Explain tables to see this information.
Execute the code:
The code in the next cell creates the Explain tables by calling the SYSPROC.SYSINSTALLOBJECTS( ) stored procedure. It then queries the system catalog to verify that the Explain tables were successfully created.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
If you attempt to perform this step with a Db2 On Cloud database, IT WILL FAIL!
Step 12: Create a new index named EMP_IDX
Overview:
An index is an object that contains pointers to rows (in a table) that are logically ordered according to the values of one or more columns (known as key columns or keys). Indexes are important because:
- They provide a fast, efficient method for locating specific rows of data in large tables
- They provide a logical ordering of the rows in a table
- They can enforce the uniqueness of records in a table
- They can force a table to use clustering storage, which causes the rows of a table to be physically arranged according to the ordering of their key column values
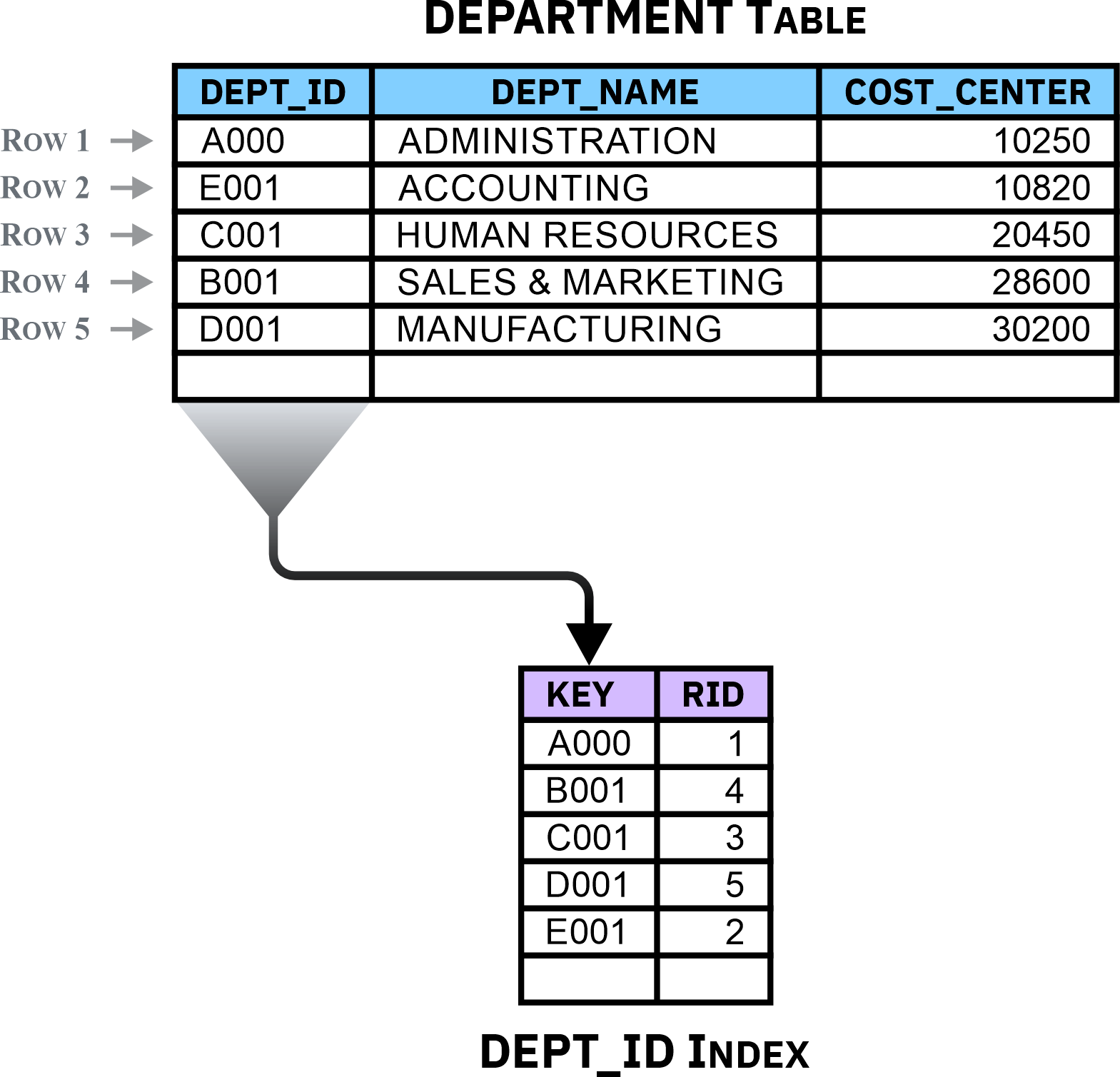
Figure 3: A simple index that has a one-column key
Although some indexes are created automatically to support a table’s definition (for example, to enforce unique and primary key constraints), indexes are typically created explicitly using the CREATE INDEX SQL statement. The basic syntax for this statement is:
CREATE < UNIQUE > INDEX [ IndexName ]
ON [ TableName ] ( [ PriColumnName ] < ASC | DESC > , ... ) >
< INCLUDE ( [ SecColumnName ] , ... ) >
where:
| • | IndexName | : | Identifies the name to assign to the index that is to be created. |
| • | TableName | : | Identifies, by name, the table the index is to be created for (and associated with). |
| • | PriColumnName | : | Identifies, by name, one or more primary columns that are to be part of the key for the index — if the index is a unique index, the combined values of each primary column specified will be used to enforce data uniqueness in the associated table. |
| • | SecColumnName | : | Identifies, by name, one or more secondary columns whose values are to be stored with the values of the primary columns, but that are not part of the index key — if the index is a unique index, the values of each secondary column specified will not be used to enforce data uniqueness. |
If the INCLUDE clause is specified with the CREATE INDEX statement used, data from the secondary columns specified will be appended to the index’s key values. By storing this information in the index (along with key values), the performance of some queries can be greatly improved. That's because if all the data needed to resolve a query can be obtained by accessing the index only, data does not have to be retrieved from the associated table. (If the data needed to resolve a query does not reside solely in an index, both the index and the associated table must be accessed.)
If the UNIQUE clause is specified with the CREATE INDEX statement used, the resulting index will be a unique index that will be used to ensure the associated table does not contain duplicate occurrences of the same values in the columns that make up the index key. If the table the index is to be created for already contains data, uniqueness is checked and enforced at the time Db2 attempts to create the index, and if records with duplicate index key values are found, the index will not be created. On the other hand, if no duplicates exist, the index will be created and uniqueness will be enforced when INSERT and UPDATE operations are performed against the associated table. (Any time uniqueness of the index key is compromised, the insert or update operation will fail and an error will be generated.)
Thus, to create an index named EMPNO_IDX for a table named EMPLOYEES whose key consists of a column named EMPNO and that includes data from a column named LASTNAME, you would execute a CREATE INDEX statement that looks something like this:
CREATE UNIQUE INDEX empno_idx ON employees(empno) INCLUDE (lastname)
A single table can contain a significant number of indexes; however, every index comes at a price. Because indexes store key column and row pointer data, additional storage space is needed for every index used. Furthermore, write performance is negatively affected — each time an INSERT, UPDATE, or DELETE operation is performed against a table with indexes, every index affected must be updated as well to reflect the changes made. Therefore, indexes should be created only when there is a clear performance advantage to having them available.
Indexes are typically used to improve query performance. So, tables that are used for data mining, business intelligence, business warehousing, and by applications that execute many (and often complex) queries but rarely modify data are prime candidates for indexes. Conversely, tables in online transaction processing (OLTP) environments or environments where data throughput is high should use indexes sparingly or avoid them altogether.
Execute the code:
The code in the next cell builds a CREATE INDEX statement and executes it to create an index named EMP_IDX. It then queries the system catalog to verify that EMP_IDX index exists.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 13: Generate Explain data for the simple query again to see if the new index improves query performance
Overview:
Now that we have created an index named EMP_IDX for the EMPLOYEE table, let's capture Explain data for the query "SELECT empno, name FROM employee" again to see if the index will improve help performance.
Execute the code:
The code in the next cell executes the EXPLAIN statement that was used earlier to generate Explain data for the query "SELECT empno, name FROM employee". It then retreives information from the EXPLAIN_STATEMENT Explain table again to see if the cost of the access plan chosen by the Db2 query optimizer is lower.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
If you attempt to perform this step with a Db2 On Cloud database, IT WILL FAIL!
Step 14: Roll back and commit a transaction
Overview:
A transaction (also known as a unit of work) is a sequence of one or more SQL operations that are grouped together as a single unit, usually within an application process. Such units are considered atomic (from the Greek word meaning “not able to be cut”) because they are indivisible — either all of a transaction’s work is carried out, or none of its work is done.
A given transaction can perform any number of SQL operations, depending upon what is considered a single step within a company’s business logic. With that said, it is important to note that the longer a transaction is — that is, the more SQL operations a transaction performs — the more problematic it can be to manage. This is especially true if multiple transactions must run concurrently.
The initiation and termination of a single transaction defines points of consistency within a Db2 database. Consequently, either the effects of all operations performed within a transaction are applied to the database and made permanent (i.e. committed), or they are backed out (rolled back) and the database is returned to the state it was in immediately before the transaction was started.
Normally, a transaction is initiated the first time an SQL statement is executed after a connection to a database has been established, or when an SQL statement is executed after a running transaction has ended. Once started, transactions can be implicitly committed using a feature known as automatic commit (in which case, each executable SQL statement is treated as a single transaction, and changes made by that statement are automatically applied to the database unless the statement fails to execute successfully). Or, they can be explicitly terminated by executing either the COMMIT or the ROLLBACK SQL statement. The basic syntax for these two statements is:
COMMIT < WORK >
or
ROLLBACK < WORK >
When the COMMIT statement is used to terminate a transaction, all changes made to the database since the transaction began are made permanent. When the ROLLBACK statement is used instead, all changes made are backed out, and the database is returned to the state it was in just before the transaction was started.
Uncommitted changes made by a transaction are usually inaccessible to other users and applications (there are exceptions) and can be backed out at any time. However, once a transaction’s changes have been committed, they become accessible to all users and applications and the only way to remove the changes made is by performing an UPDATE or DELETE operation.
With Python and Jupyter Notebook, the ibm_db.commit( ) and ibm_db.rollback( ) application programming interfaces (APIs) in the ibm_db library can be used to terminate transactions. These APIs eliminate the need to prepare and execute COMMIT and/or ROLLBACK SQL statements. In addition, the ibm_db.autocommit( ) API can be used to determine if automatic commit behavior is enabled or disabled, as well as turn this behavior ON or OFF.
Execute the code:
The code in the next cell executes the ibm_db.autocommit( ) API to determine whether automatic commit behavior is ON or OFF — if this behavior is ON, the ibm_db.autocommit( ) API is executed again to turn it OFF. Then, the code builds and executes an INSERT statement that adds a record to the EMPLOYEE table created earlier and queries the table to verify the record was added — it can see the record because it owns the transaction that performed the INSERT operation. However, in most cases (there are exceptions), other applications will NOT be able to see the record until the transaction is committed.
After verifying the record was added, the code executes the ibm_db.rollback( ) API to back out the change made by the INSERT operation (transaction). Then, it queries the EMPLOYEE table again to confirm the record no longer exists. Next, it executes the INSERT statement once more and executes the ibm_db.commit( ) API to end the transaction and make the change permanent. Then, it queries the EMPLOYEE table again to verify the record exists. Finally, it executes the ibm_db.autocommit( ) API once more to turn automatic commit behavior ON.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs. (There are a lot of different actions taking place in this example, so please review the code carefully.)
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Section 3. Advanced topics
Step 1: Create two User Defined Functions
Overview:
User defined functions (UDFs) are special objects that can be used to extend and enhance the support provided by the built-in functions available with Db2. But, unlike built-in functions, UDFs can take advantage of operating system calls and the Db2 administrative application programming interfaces (APIs) Db2 provides. Several different types of UDFs can be created:
- SQL scalar: A function whose body is written entirely in SQL and Db2 SQL Procedural Language (SQL PL) that returns a single value each time it is called. (SQL PL is a language extension of SQL that consists of statements and language elements that can be used to implement procedural logic in user defined functions and stored procedures. You can learn more about SQL PL here: SQL Procedural Language (SQL PL).)
- SQL table: A function whose body is written entirely in SQL and SQL PL that returns a result set, in the form of a table, each time it is called.).
- Sourced (or Template): A function that is based on another function (referred to as the source function) that already exists. Sourced functions can be columnar, scalar, or tabular in nature; they can also be designed to overload specific operators such as +, –, *, and /. When a sourced function is invoked, all arguments passed to it are converted to the data types the underlying source function expects, and the source function itself is executed. Upon completion, the source function performs any conversions necessary on the results produced and then returns them to the calling application.
- External scalar: A function whose body is written in a high-level programming language like C, C++, or Java that returns a single value each time it is called. The function itself resides in an external library and is registered in the database, along with any related attributes.
- External table: A function whose body is written in a high-level programming language that returns a result set, in the form of a table, each time it is called. As with external scalar functions, the function itself resides in an external library and is registered in the database, along with any related attributes.
- OLE DB External Table: A function whose body is written in a high-level programming language that can access data from an Object Linking and Embedding Database (OLE DB) provider and return a result set in the form of a table.
Once a UDF is created (and registered with a database), it can be used anywhere a comparable built-in function can be used — UDFs are created (and registered with a database) using the CREATE FUNCTION SQL statement. Several forms of this statement are available; the appropriate form to use is determined by the function type desired. The basic syntax for the form of this statement that is used to create an SQL scalar function is:
CREATE FUNCTION [ FunctionName ]
(< < ParameterType > [ ParameterName ] [ DataType ] , ... > )
RETURNS [ OutputDataType ]
< LANGUAGE SQL >
< READS SQL DATA | CONTAINS SQL | MODIFIES SQL DATA >
[ < BEGIN ATOMIC > SQLStatements ; < END > ]
RETURN [ ReturnStatement ]
Similarly, the basic syntax for the form of the CREATE FUNCTION statement that is used to create an SQL table function is:
CREATE FUNCTION [ FunctionName ]
(< < ParameterType > [ ParameterName ] [ DataType ] , ... > )
RETURNS TABLE ( [ ColumnName ] [ ColumnDataType ] , ... )
< LANGUAGE SQL >
< READS SQL DATA | CONTAINS SQL | MODIFIES SQL DATA >
[ < BEGIN ATOMIC > SQLStatements ; < END > ]
RETURN [ ReturnStatement ]
where:
| • | FunctionName | : | Identifies the name to assign to the function that is to be created. |
| • | ParameterType | : | Indicates whether the parameter specified in the ParameterName parameter is an input parameter (IN), an output parameter (OUT), or both an input and an output parameter (INOUT). |
| • | ParameterName | : | Identifies the name to assign to one or more function parameters. |
| • | DataType | : | Identifies the data type of the parameter specified in the ParameterName parameter. (You can learn more about the data types available with Db2 here: Data types) |
| • | OutputDataType | : | Identifies the data type the function is expected to return. |
| • | ColumnName | : | Identifies one or more names to assign to the column(s) the function is expected to return (if the function is an SQL table function). |
| • | ColumnDataType | : | Identifies the data type the function expects to return for each column specified in the ColumnName parameter. |
| • | SQLStatements | : | Identifies one or more SQL statements that are to be executed when the function is invoked — if two or more statements are used, they should be enclosed with the keywords BEGIN ATOMIC and END and each statement must be terminated with a semicolon (;). |
| • | ReturnStatement | : | Identifies the RETURN statement that is to be used to return data to the user, application, or SQL statement that invoked the function. |
The < CONTAINS SQL | READS SQL DATA | MODIFIES SQL DATA > clause identifies the types of SQL statements that can be used in the body of the function: if the CONTAINS SQL clause is specified, the function cannot contain SQL statements that read or modify data, if the READS SQL DATA clause is specified, the function cannot contain SQL statements that modify data; and if the MODIFIES SQL DATA clause is specified, the function can contain SQL statements that both read and modify data.
Thus, to create an SQL scalar function named CONVERT_CTOF( ) that accepts a temperature value in degrees Celsius as input and returns a corresponding temperature value in degrees Fahrenheit, you would execute a CREATE FUNCTION statement that looks something like this:
CREATE FUNCTION convert_ctof (IN temp_c FLOAT) RETURNS FLOAT RETURN FLOAT((temp_c * 1.8) + 32)
On the other hand, to create an SQL table function named DEPT_EMPLOYEES( ) that accepts a department code as input and returns a result set, in the form of a table, that contains basic information about every employee who works in the department specified, you would execute a CREATE FUNCTION statement that looks more like this:
CREATE FUNCTION dept_employees (deptno CHAR(3)) RETURNS TABLE (empno INTEGER, name VARCHAR(30)) LANGUAGE SQL READS SQL DATA BEGIN ATOMIC RETURN SELECT empno, name FROM employee AS e WHERE e.dept = dept_employees.deptno; END
Execute the code:
The code in the next cell executes both of the CREATE FUNCTION statements provided as examples. It then queries the system catalog to verify that both functions exist.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 2: Invoke the User Defined Functions created earlier
Overview:
The way in which a user defined function (UDF) can be used is largely dependent upon the function type. A scalar function optionally accepts arguments and returns a single scalar value each time the function is called. Therefore, and SQL scalar function can be used wherever an expression can be used. (An expression is a specification, which can include operators, operands, and parentheses, that a Db2 database can evaluate to one or more values, or to a reference to some database object.)
Table functions, on the other hand, return rows and columns of data much like a table created with a simple CREATE TABLE statement would return when queried. Consequently, a table function can be used only in the FROM clause of an SQL statement.
Execute the code:
The code in the next cell creates and populates a table named WEATHER. Then, it then builds and executes SQL statements that illustrate how each of the user defined functions (UDFs) created in the previous step might be used.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 3: Create an SQL procedure
Overview
Every time an SQL statement is executed against a Db2 database that resides on a remote server, the statement itself is sent over a network to the server for processing. The database at the server then executes the statement and returns the results, again over the network, to the appropriate user/application. This means that two messages must travel over the network for every SQL statement that gets executed. By breaking monolithic applications into separate parts and storing those parts that perform a relatively large amount of database activity with little or no user interaction directly on the database server itself (in the form of a stored procedure), the amount of data that needs to flow across the network can be greatly reduced. In some cases, this approach can also enhance application performance, since the portions of the code that interact with the database are physically stored on the server where computing power and centralized control can deliver quick, coordinated data access.
Stored procedures allow work that is done against a database to be encapsulated and stored in such a way that it can be executed directly at the database server by any application or user who has the appropriate authority. And, because only one SQL statement is needed to invoke a stored procedure (the CALL statement), fewer messages are transmitted across the network — only the data that is actually needed at the client is sent across. It is also important to note that when a stored procedure is used to implement a specific business rule, the logic needed to apply that rule can be incorporated into any application simply by invoking the procedure. Thus, the same business rule logic is guaranteed to be enforced across multiple applications. And if business rules change, only the logic in the procedure has to be modified — applications that call the procedure do not have to be altered.
Two different types of stored procedures can be created:
- SQL (or Native SQL): A stored procedure whose body is written entirely in SQL or SQL Procedural Language (SQL PL). (SQL PL is a language extension of SQL that consists of statements and language elements that can be used to implement procedural logic in user defined functions and stored procedures. You can learn more about SQL PL here: SQL Procedural Language (SQL PL).)
- External: A stored procedure whose body is written in a high-level programming language such as Assembler, C, C++, COBOL, Java, REXX, or PL/I that resides in an external library that is accessible to DB2; external stored procedures must be registered in a database, along with all their related attributes, before they can be invoked.
While SQL procedures offer rapid application development and considerable flexibility, external stored procedures can be much more powerful because they can exploit system calls and the administrative application programming interfaces (APIs) that are provided with Db2. However, this increase in functionality makes them much more difficult to produce. In fact, the following steps are required to create an external stored procedure:
- Construct the body of the procedure, using a supported high-level programming language.
- Compile and link the procedure to create a shared (dynamic-link) library.
- Debug the procedure, repeating steps 1 and 2 until all problems have been resolved.
- Physically store the library containing the procedure on the database server.
- Modify system permissions for the library so that all users with the proper authority can execute it.
- Register the procedure with the appropriate Db2 database (running on the server).
Regardless of whether stored procedures are written using SQL or a high-level programming language, they must perform the following tasks, in the order shown:
- Accept any input parameter values the calling application supplies.
- Perform whatever processing is appropriate (typically, this involves executing one or more SQL statements as a single operation).
- Return output data (if data is to be returned) to the calling application — at a minimum, a stored procedure should return a value that indicates whether it executed successfully.
Stored procedures are created by executing the CREATE PROCEDURE statement. Two forms of this statement are available, and the appropriate form to use is determined by the stored procedure type. The basic syntax for the form of the CREATE PROCEDURE statement that is used to create an SQL stored procedure looks something like this:
CREATE PROCEDURE [ ProcedureName ]
(< < ParameterType > [ ParameterName ] [ DataType ] , ... > )
< LANGUAGE SQL >
< DYNAMIC RESULT SETS [ 0 | NumResultSets ] >
< READS SQL DATA | CONTAINS SQL | MODIFIES SQL DATA >
[ < BEGIN ATOMIC > SQLStatements ; < END > ]
where:
| • | ProcedureName | : | Identifies the name to assign to the procedure that is to be created. |
| • | ParameterType | : | Indicates whether the parameter specified in the ParameterName parameter is an input parameter (IN), an output parameter (OUT), or both an input and an output parameter (INOUT). |
| • | ParameterName | : | Identifies the name to assign to one or more function parameters. |
| • | DataType | : | Identifies the data type of the parameter specified in the ParameterName parameter. (You can learn more about the data types available with Db2 here: Data types) |
| • | NumResultSets | : | Identifies the number of result sets the procedure returns (if any). |
| • | SQLStatements | : | Identifies one or more SQL statements that are to be executed when the procedure is invoked — if two or more statements are used, they should be enclosed with the keywords BEGIN and END and each statement must be terminated with a semicolon (;). |
Thus, to create an SQL procedure named HIGH_EARNERS( ) that returns a list of employees whose salary exceeds the average salary (in the form of a result set), along with the average employee salary, you might execute a CREATE PROCEDURE statement that looks something like this:
CREATE PROCEDURE high_earners (OUT avg_salary FLOAT) LANGUAGE SQL DYNAMIC RESULT SETS 1 READS SQL DATA BEGIN DECLARE c1 CURSOR WITH RETURN FOR SELECT name, salary FROM employee WHERE salary > avg_salary ORDER BY salary DESC; DECLARE EXIT HANDLER FOR NOT FOUND SET avg_salary = 0; SET avg_salary = 0; SELECT AVG(salary) INTO avg_salary FROM employee; OPEN c1; END
When this particular CREATE PROCEDURE statement is executed, the SQL procedure produced will return an integer value (in an output parameter called AVG_SALARY) and a result set that contains the name and salary of each employee whose salary is higher than the average salary paid to employees. Key elements that control this behavior include:
- Specifying the DYNAMIC RESULT SETS 1 clause with the CREATE PROCEDURE statement used, indicating the SQL procedure is to return a one result set.
- Defining a cursor within the procedure body (and specifying the WITH RETURN FOR clause in the DECLARE CURSOR statement used) so a result data set will be returned.
- Querying the EMPLOYEE table using the built-in AVG( ) scalar function to obtain average salary information.
- Opening the cursor (which causes the query that obtains employee salary information to be executed and a result data set to be produced).
- Returning the average salary to the calling statement (in the output parameter named AVGSALARY) and leaving the cursor that was created open so the data in the result set produced can be accessed by the calling application.
Execute the code:
The code in the next cell executes the CREATE PROCEDURE statement that was provided as an example. It then queries the system catalog to verify that the procedure exists.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 4: Invoke a procedure
Overview
Once a procedure has been created and registered with a database (via the CREATE PROCEDURE statement), it can be invoked by executing the CALL statement. The basic syntax for this statement is:
CALL [ ProcedureName ]
( [ InputParameter ] | [ OutputParameter ] | DEFAULT | NULL , ... )
where:
| • | ProcedureName | : | Identifies, by name, the procedure that is to be invoked. |
| • | InputParameter | : | Identifies one or more values (or application variables containing values) that are to be passed to the procedure as input parameters. |
| • | OutputParameter | : | Identifies one or more values (or application variables containing values) that are to receive values that will be returned as output from the procedure. |
Like other dynamic SQL statements that can be prepared and executed at runtime, CALL statements can contain parameter markers in place of constants and expressions. (You may recall that parameter markers are represented by the question mark character (?) and indicate the position in an SQL statement where the current value of one or more application variables are to be substituted at the time the statement is executed.)
Thus, the SQL procedure named HIGH_EARNERS( ) that was created earlier can be invoked by executing a CALL statement that looks something like this:
CALL high_earners (?)
While the CALL SQL statement can be prepared and executed (using parameter markers) with Python and Jupyter Notebook, there is no way to retrieve any data and/or result set(s) the procedure being called might produce. Instead, the ibm_db.callproc( ) application programming interface (API) in the ibm_db library must be used to invoke procedures when Python or Jupyter Notebook is used. The syntax for this API is:
ibm_db.callproc ( IBM_DBConnection connectionID, string procName [, tuple procParams ] )
where:
If the execution of this API is successful, an IBM_DBStatement object, (or a tuple containing an IBM_DBStatement object), followed by a potentially modified tuple containing a copy of the parameter values that were supplied for the procPrams parameter when the API was called, will be returned. (Values for IN parameters are left untouched whereas values for OUT and INOUT parameters may have been changed by the procedure.) If the execution of this API is unsuccessful, the value None will be returned instead.
Execute the code:
The code in the next cell executes both the CALL SQL statement and the ibm_db.callproc( ) API to invoke the procedure named HIGH_EARNERS( ) that was created earlier.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Section 4. Lab environment clean up
Step 1: Remove the tables used by the Db2 EXPLAIN facility (if using IBM Db2 Community Edition)
Overview:
In Step 11 of Section 2, the tables that are needed for the Explain facility were created by calling the SYSPROC.SYSINSTALLOBJECTS( ) stored procedure. As pointed out in Section 10, the SYSPROC.SYSINSTALLOBJECTS( ) procedure is used to both create and drop the database objects that are required by a specific Db2 tool. You may recall that the SQL syntax used to execute this procedure is:
CALL SYSPROC.SYSINSTALLOBJECTS ( [ ToolName ], [ Action ], [ TablespaceName ], [ SchemaName ] )
where:
| • | ToolName | : | Identifies the name of the tool that database objects are to be created or deleted for. Valid values include:
|
| • | Action | : | Specifies the action that is to be taken with the required objects. Valid values include:
|
| • | TablespaceName | : | Identifies, by name, the table space in which the database objects are to be created. (In most cases, the table space named SYSTOOLSPACE is used). |
| • | SchemaName | : | Identifies, by name, the schema in which the database objects are to be created. (In most cases, the schema name SYSTOOLS is used.) |
Thus, to delete the database objects that are required for the Explain facility (i.e., the Explain tables), you would execute an SQL statement that looks like this (assuming they were created in the default table space and schema):
CALL SYSPROC.SYSINSTALLOBJECTS ('EXPLAIN', 'D', CAST (NULL AS VARCHAR(128)), CAST (NULL AS VARCHAR(128)))
Execute the code:
The code in the next cell deletes the Explain tables that were created earlier by calling the SYSPROC.SYSINSTALLOBJECTS( ) stored procedure. It then queries the system catalog to verify that the Explain tables were successfully removed.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
If you attempt to perform this step with a Db2 On Cloud database, IT WILL FAIL!
Step 2: Query the system catalog to see all user-defined objects created in this lab
Overview:
Before proceeding with the removal of all of the user-defined objcets that were created in this lab, let's query the system catalog to see exactly what objects were created. (Once the objects have been deleted, we can query the system catalog again to verify the deletion operation was successful.)
As we saw earlier, you can obtain a list of the tables and views that have been defined in a database by querying the system catalog view named SYSCAT.TABLES. You can obtain a list of the indexes that have been created by querying the SYSCAT.INDEXES system catalog view. And finally, you can obtain a list of the user defined functions (UDFs) and procedures that have been defined by querying the system catalog view named SYSCAT.ROUTINES.
Execute the code:
The code in the next cell queries the SYSCAT.TABLES view, the SYSCAT.INDEXES view, and the SYSCAT.ROUTINES view and returns a list of the tables, views, indexes, UDFs, and procedures that were created in this lab.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 3: Remove all user-defined objects that were created earlier from the database
Overview:
While it is important to be able to create and modify database objects in a Db2 database, it is equally important to be able to delete objects when they are no longer needed. Most user-defined objects can be removed from a Db2 database by executing some form of the DROP SQL statement. The basic syntax for this statement is:
DROP [ObjectType ] [ ObjectName ]
where:
| • | ObjectType | : | Identifies the type of object that is to be deleted (dropped). |
| • | ObjectName | : | Identifies, by name, the object that is to be deleted (dropped). |
Thus, if you wanted to delete a table named SALES, you could do so by executing a DROP statement that looks like this:
DROP TABLE sales
It is important to keep in mind that when an object is dropped, its removal may affect other objects that are dependant upon its existence. (For instance, if a table a view is based on is dropped, the view will no longer be valid.) In some cases, when an object is dropped, all objects that are dependent upon the object are dropped as well — in other cases, an object can only be dropped after all other objects that are dependent upon its existence have been deleted.
Execute the code:
The code in the next cell drops (removes) the view, tables, user defined functions, and procedure that were created earlier.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 4: Query the system catalog to again to confirm that all user-defined objects created in this lab have been deleted
Overview:
Now that all of the user-defined objcets that were created in this lab have been deleted, let's query the system catalog once more to confirm the deletion operations were successful.)
Execute the code:
The code in the next cell queries the SYSCAT.TABLES view, the SYSCAT.INDEXES view, and the SYSCAT.ROUTINES view again and attempts to return a list of the tables, views, indexes, UDFs, and procedures that were created in this lab. If the DROP statements executed in the previous step were successful, each query executed should return the value "No records found.".
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.
Step 3: Terminate the database connection
Overview:
When a database connection is established, it remains in effect until it is explicitly terminated or until the application that established the connection ends. That said, it is good programming practice to explicitly terminate any database connections that are open before ending an application returning control to the operating system. While this is typically done as part of the "exit and cleanup" work of an application, it can also be done any time an error is raised that forces an application to terminate prematurely.
Execute the code:
The code in the next cell terminates the Db2 database connection established earlier and returns control to the operating system.
- Select the code cell below and carefully read through the comments. This will help you understand the actions the code performs.
- When you are ready, click on the
button or press Shift+Enter to execute the code.