(20 min) Using RethinkDB in Production for SageMathCloud
(10 min) SageMathCloud
SageMath: open source python math software project I started in 2004
Sage Days 70 all week (in Berkeley -- picture)
SageMathCloud: 100% open source. Like Google Docs for Latex, IPython notebooks, SageMath, Terminals, Teaching (course management), etc.
Stack: Linux, React.js, RethinkDB, Node.js, SageMath/Python, CodeMirror, CoffeeScript
4000 daily active users; nearly 1000 simultaneous users
RethinkDB:
Switched from Cassandra to RethinkDB this summer.
Setup:
6 GCE nodes (quad-core n1-standard-4)
about 20+ tables storing about 5 million documents
replication factor 3, sharding of 3
storage in persistent (network-mounted) SSD.
Often around 5000 simultaneous changefeeds.
Backup: frequent full dumps to a compressed filesystem, snapshot via bup (=git+more), rsync to GCE (google cloud storage) and off-site USB drive. Incrementals are usually a single git pack file.
The Rethinkdb team is amazing at fixing absolutely all issues I encountered.
SMC Demo:
Change name and see change in another browser.
Show changing project title and that appearing in another browser.
Draw a 3d plot in a sage worksheet
Open a Jupyter notebook -- demo sync and history
No REST/API calls; instead, set entries in a table, back-end sees it, makes table change, all parts of all front-ends simultaneously see that (do a demo of project restart).
(10min) How SageMathCloud uses Changefeeds
Inspiration: Facebook's GraphQL (but simpler)
Goal: Have declarative client-side queries and database schema; instant notifications about changes.
Motivation: make front-end development easier, and simplify code connecting the front-end to back-end (one declaration instead of messages flying all over)
Browser (or iOS/Android at some point) client query:
JSON object that describes what result should look like; null's get filled in.
{table:{foo:bar, stuff:null}}gets one record in table wherefoo="bar"and{table:[{foo:bar, stuff:null}]}gets them all.If
changes=true, then any time RethinkDB table changes, client gets updates, and anytime client makes changes, they get pushed to back-end to RethinkDB.Tables can be "virtual", and not correspond to actual RethinkDB tables. e.g., different permissions, or involving multiple tables (so joins, technically; they also have a killfeed).
Show
schema.coffee.Text editing: describe algorithm based on the above, which isn't deployed yet.
SCRATCH
(5 min) Running RethinkDB in production
(5 min) The setup
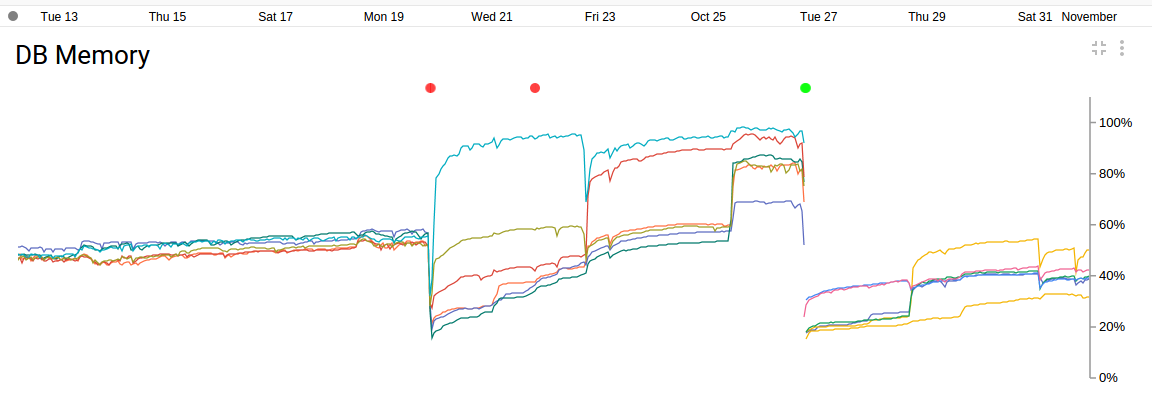
Until mid-Oct we used 6 dual-core n1-highcpu-2, but had to switch to 6 quad-core n1-standard-4.
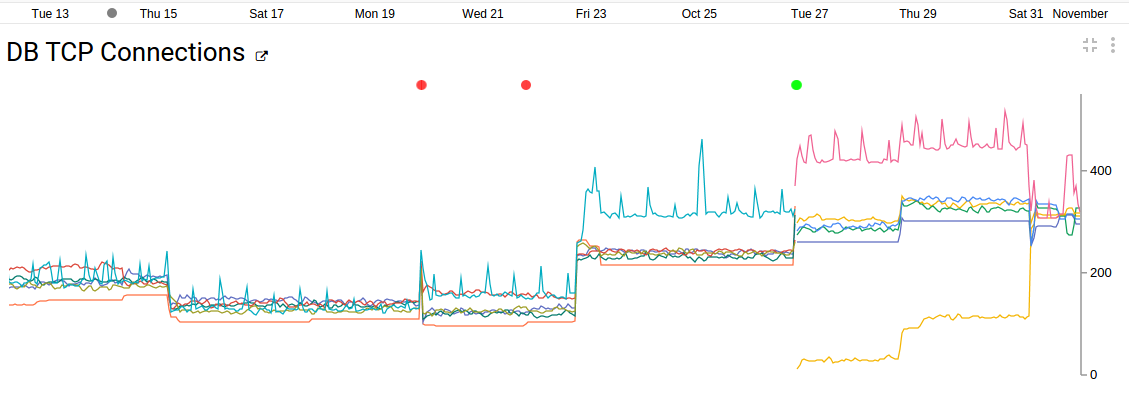
We use 6 GCE nodes, with about 20+ tables, replication factor 3, sharding of 3, persistent (network-mounted) SSD.
Often have around 5000 changefeeds.
Had some trouble with automatic failover (I test in production to be sure it is working!).
The Rethinkdb team was amazing in fixing absolutely all bugs I found.
Backups by dumping most tables frequently and using bup (=git+more) to backup, then rsync to cloud storage and offsite USB drive.
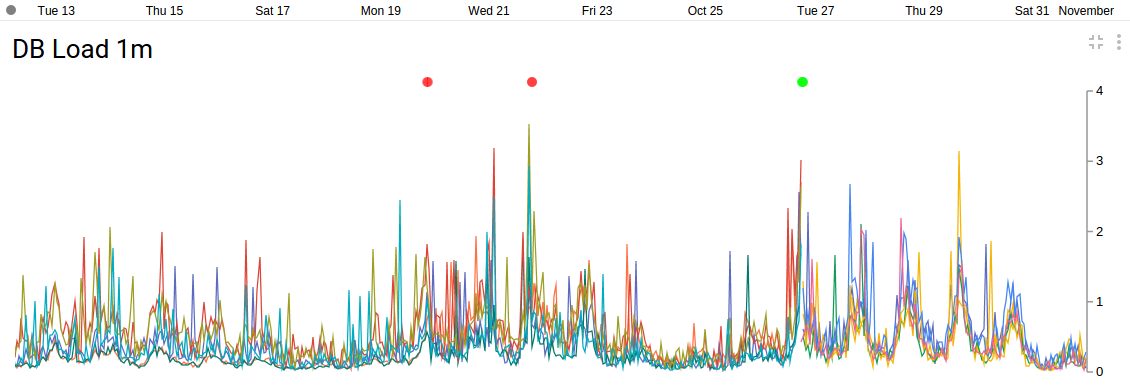
(5 min) Instrumentation Data
About 3 week of data for November 2015 across 6 nodes. At one point (with 6 n1-highcpu-2's), we hit a threshhold (with around 850 simultaneous users) and the backend collapsed and a new node had to be added