ubuntu2204
Design a Phone with the Materials Project
Today, you will leverage the properties computed by the Materials Project to design a mobile phone.
The Materials Project dataset
The Materials Project is an organisation based at Lawrence Berkeley National Laboratory that aims to calculate the properties of all known materials. With this knowledge, we can accelerate the discovery of new materials without having to perform any experiments. All our calculations are performed on supercomputers, allowing our computations, data, and algorithms to run at unparalleled speed.
The dataset you will be exploring has been compiled from the Materials Project database of calculated material properties. It only includes crystalline materials (think diamond, metals, metal oxides such as rust, etc) and not amorphous materials (such as rubber, plastics, or glass). In the database you will be exploring, we have only included the properties that are useful for choosing mobile phone components:
material_id: This is the identification number of the material. You can use this to search the material on the Materials Project website. For example, you can see more information about the first material in the dataset (mp-770629) by going to the following url: https://materialsproject.org/materials/mp-770629formula: The chemical formula indicating the number and type of elements in the material.cost: The cost of the raw elements in the material in $/kg.scarcity: How scarce the raw elements are. Larger numbers indicate that the elements will be harder to find and occur less frequently in the earths crust.density: The density of the material in g/cm3.conductivity: The conductivity of the material. Larger numbers indicate the material is more conductive.transparency: The transparency of the material. Larger numbers indicate the material is more transparent.hardness: The hardness of the material. Larger numbers indicate stronger materials.voltage: The maximum obtainable voltage if the material is used in a battery.capacitance: The maximum obtainable capacitance if the material is used in a battery.
To start with, let's load the dataset as a Pandas DataFrame.
Manipulating and examining pandas DataFrame objects
You can think of DataFrame objects as a type of "spreadsheet" object in Python. DataFrames have several useful methods you can use to explore and clean the data, some of which we'll explore below.
Inspecting the dataset
The head() function prints a summary of the first few rows of a data set. You can scroll across to see more columns. From this, it is easy to see the types of data available in in the dataset. Some values are NaN which means 'not a number' to indicate missing data. Missing data might mean that we have not calculated that property yet, for example.
You can immediately see that not all properties are available for every material. For example, the hardness, voltage, and capacitance values are empty (set to NaN which means 'not a number') for the first 5 materials shown above.
Sometimes, if a dataset is very large, you will be unable to see all the available columns. Instead, you can see the full list of columns using the columns attribute:
Indexing the dataset
We can access a particular column of DataFrame by indexing the object using the column name. For example:
Filtering the dataset
Pandas DataFrame objects make it very easy to filter the data based on a specific column. We can use the typical Python comparison operators (==, >, >=, <, etc) to filter numerical values. For example, let's find all entries where the cell density is greater than 5. We do this by filtering on the density column.
Note that we first produce a series of True and False depending on the comparison. We can then use this filter to index the DataFrame.
Task 1: Data cleaning
The first thing you should do with any dataset is make sure the data is formatted correctly and makes sense. If you start with garbage data, whatever analysis you perform is likely to produce garbage results. Even the Materials Project isn't immune to malformed or nonsensical data now and again.
Pandas DataFrame's include a function called describe() that helps determine statistics for the various numerical/categorical columns in the data. You should use the describe() function to get a feel for the dataset. Look at the min and max values for each of the columns. Do you see anything strange?
If you noticed anything strange about the "density" column, well done. The density of a material is its mass per volume, therefore it doesn't make sense to have negative density — as a side note, negative density materials would allow us to create wormholes through space and time but that is beyond the scope of this tutorial.
We can look into this discrepancy in more detail by plotting a histogram (distribution plot) of the density values. To do this, run the plot.hist() command on the "density" column. Create a histogram with 50 bins by using the bins= argument. Do you notice anything odd about the distribution?

That peak at around -10 indicates a signficant amount of the density data has been entered into the database incorrectly. We should remove all these outliers before doing any further analysis. To do this, we will overwrite the material_data variable with a dataframe containing materials with positive densities only.
Let's check to make sure all negative density values were removed by running describe() again.
The Challenge: Designing a Mobile Phone
A mobile phone is constructed of multiple components. Each component has different material property requirements, summarised in the graphic below.
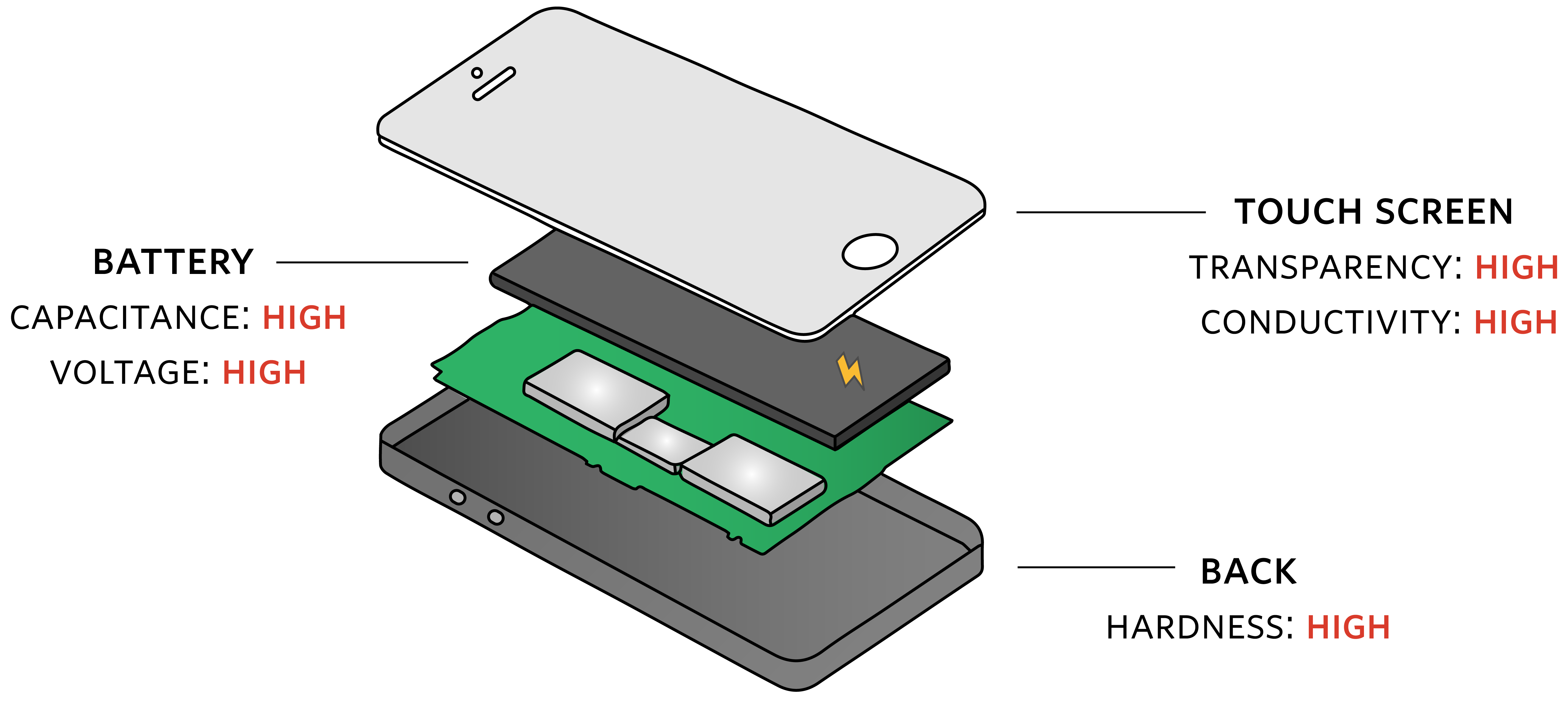
In addition to these requirements, all materials should also be:
As cheap as possible (i.e., low cost).
As available as possible (i.e., low scarcity).
As light as possible (i.e., low density).
Your task in this session will be to choose materials that satisfy the above requirements. You choices will then be assessed to determine if they will make a good mobile phone.
The mobile phone manufacturers we are using have a hard limit on the scarcity of the materials they use. You must make sure that the materials you choose are in the bottom 50 % of the scarcity of all materials.
Task 2: Calculating the cost per volume of material
In our dataset, the cost for each material is given per unit mass (in $/kg). However, when building a mobile phone, we generally know the volume of material we will need, not the mass. You should therefore add a new column to the dataset containing the cost per unit volume (in $/cm3).
To calculate the cost per volume, you will need to use the density (in g/cm3). The equation is:
BUT you will need to first convert the density to kg/cm3.
Aim: Create a new column called volume_cost that contains the cost per volume in $/cm3.
Hints:
In Pandas, you can add a new column by giving it a name and assigning it the value of a mathematical operation using other column names as variables. For example, to make a new column "A times B" that contains the product of columns 'A' and 'B', you could write
You can check that the new column was added correctly buy calling the head() function on the dataframe.
Task 3: Choosing a protective casing material
How many times have you dropped your mobile phone? Did the screen crack? Imagine if the back of your phone was made of glass... it would be much more prone to breaking. Now you can understand the importance of having a hard and durable material to make up the protective back casing.
You need to decide what material you will use for the back of your phone. It needs to be hard but also cheap because you will use a lot of it. It should also have low elemental scarcity.
The protective casing will use 5 cm3 of material.
Requirements:
Hardness: high (greater than 200)
Total cost: low (less than $ 0.05)
Scarcity: low (in the bottom 50% of all materials)
Aim: Choose a material for the back of your phone. You should assign the material_id of your chosen material to the back_material variable.
Hints: You can chain filters together using & (and) and | (or). For example,
checks whether the density falls between 10 and 20, whereas
checks whether the density falls outside the 10-20 range. The brackets around the different clauses are required.
The above lines will return a Series of True and False values for the rows that match or don't match the filter. To get a dataframe with the rows you want, you should index your dataframe with the filter. I.e.
Once you have decided on a protective casing material. Fill in the cell below with the material_id of the material of your choice.
Task 4: Choosing a battery material
The discovery of lithium-ion batteries is one of the greatest scientific achievements of the last 50 years and was recently recognised by 2019 Nobel Prize in Chemistry.
You need to choose a battery material for your phone using the battery properties calculated by the Materials Project. It should have a high voltage and large capactiance so that your customers can continue browsing TikTok as long as possible. Like all other materials in your phone, it should also be cheap and have low elemental scarcity.
The battery will use 3 cm3 of material.
Requirements:
Capacitance: high (greater than 320)
Voltage: high (greater than 3.0)
Total cost: low (less than $ 0.1)
Scarcity: low (in the bottom 50% of all materials)
Aim: Choose a material for the battery of your phone. You should assign the material_id of your chosen material to the battery_material variable.
Once you have decided on a battery material. Fill in the cell below with the material_id of the material of your choice.
Task 5: Choosing a conductive transparent coating
You might not notice it but the screen of every phone is covered in a remarkable material. Like a metal, this material is highly conductive so it can register the precise position of your finger; however, unlike a metal it is completely transparent and allows you to see the screen underneath. These materials are called "transparent conductors" and have also been used in windshields of fighter jets and supermarket freezer windows to stop them frosting up.
You need to choose a transparent conducting material for your phone using the properties calculated by the Materials Project. It should have a high transparency and large conductivity. Like all other materials in your phone, it should also be cheap and have low elemental scarcity.
The transparent coating will use 1 cm3 of material.
Requirements:
Transparency: high (greater than 0.8)
Conductivity: high (greater than 80)
Total cost: low (less than $ 1)
Scarcity: low (in the bottom 50% of all materials)
Aim: Choose a transparent coating for your phone. You should assign the material_id of your chosen material to the transparent_material variable.
Once you have decided on a transparent coating material. Fill in the cell below with the material_id of the material of your choice.
Task 6: Will your phone make it to market?
We have designed an advanced algorithm to determine whether your phone will be commercially successful. Run the cell below to evaluate your phone...
Bonus Task: Materials discovery using machine learning
As you may have noticed, not all properties (conductivity, voltage, hardness, etc) have been computed for every material in our dataset. In this last exercise, you will train a machine learning model to predict the hardness of a material based only on its density. You will then fill in the missing hardness data and look for promising materials using your predicted data.
We will train our machine learning model to predict hardness based only on density. To start with, we have to prepare our training data. We need to filter our dataframe to only include the materials for which the hardness has already been calculated. I.e., the hardness column does not contain NaN.
You can achieve this using the pandas isna function. For example:
will return a Series of True and False corresponding to whether the "voltage" column is NaN. We are looking for the materials which are NOT NaN, therefore we can invert the filter using ~. For example:
Finally, remember we need to index our dataframe using the filter to get the final results:
Below, you should complete the cell so that material_data_hardness includes only the materials for which the "hardness" data is available.
Next, we need to partition the data into two sets. The first is the training data called X, in this case containing the density for each material. The second set should contain the target property that we are trying to predict, called y.
Now we are ready to train our machine learning model. For this we will be using the scikit-learn library which implements a variety of different machine learning models and other analysis tools. In this example we will only trial a single model but it is good practice to trial multiple models to see which performs best for your machine learning problem. A good "starting" model is the random forest model. Let's create a random forest model.
We can now train our model to use the input features (X) to predict the target property (y). This is achieved using the fit() function.
That's it, you have just trained your first machine learning model!
Next, we need to assess how the model is performing. To do this, we can ask the model to predict the target property for every entry in our original dataframe.
The y_pred variable now contains the predicted hardness for our training set of materials. We can see how the model is performing by calculating the root mean squared error of our predictions. To do this, Scikit-learn provides a mean_squared_error() function to calculate the mean squared error. We then take the square-root of this to obtain our final performance metric.
Does this value seem high to you? How does it compare to the average hardness value of the data set?
Alternatively, we can plot the actual hardness values against the values predicted by our model. In the plot the below, each point has been colored by the density of the original material.

As you can see, the model performs reasonably well! If the model showed perfect performance then all the points would line up along the dashed white line.
Predicting the hardness of novel materials
Finally, we can use the predict function of the model to predict the hardness of all the materials in our original dataset, not just those for which training data was available.
In the cell below, we create a new column called "hardess_predicted" that contains the hardness predicted by our machine learning model.
Let's check to make sure the dataframe contains the new column.
Discovering new materials using predicted data
We can now look for new protective casing materials using the predicted data.
Aim: Find the hardest material for which we didn't previously have a hardness value. Does this seem like a good choice of protective casing?
Hint: First filter the dataframe to find materials where the hardness column is NaN (i.e., using pd.isna as we did at the beginning of the bonus task). You can then find the maximum value of the filtered dataframe using:
Notebook developed by: Alex Ganose, Ryan Kingsbury, Jianli Cheng
Some notebook modifications made by: Alisa Bettale